Chrome et Googlebot, quelle interaction entre les deux services ?
Ecrit par Peak Ace
le
Le 15 mars dernier, le cabinet de conseil Stone Temple Consulting publiait une étude dont l’objectif était d’affirmer que les données produites par Google Chrome n’étaient pas utilisées pour découvrir de nouvelles urls et donc enrichir son index. L’écosystème de la firme américaine est une véritable mine d’or qui comptabilise de multiples services et plateformes, dont YouTube, Android, Google Play, Google Maps, Google Analytics…
Google Chrome, entre autres, avec 750 millions d’utilisateurs actifs mensuels dans le monde est le navigateur le plus utilisé avec ses 92% de parts de marché. Dans ce contexte, beaucoup s’imaginent que Google exploite le navigateur Chrome en tant que source de données, parmi beaucoup d’autre, pour crawler de nouvelles urls . C’est sur cette base que se fonde l’étude qu’a conduite Stone Temple Consulting, dont voici les principales étapes et conclusions.
Méthodologie employée :
L’agence a créé 4 articles publiés comme pages orphelines (2 articles et 2 pages de contrôle). Les pages ont été intégrées par FTP, et non via un CMS, afin que le processus d’intégration n’envoie aucun signal quel qu’il soit à Googlebot.
Une semaine après la mise en ligne, avec vérification quotidienne des logs pour s’assurer que qu’aucune visite de Googlebot n’ait eu lieu, 27 personnes ont accédé aux pages en copiant/collant les urls dans Chrome avec comme consigne principale de désactiver toutes leurs extensions.
Résultats :
Googlebot n’est jamais venu visiter les pages tests. À noter, cependant, que deux utilisateurs tests n’ont pas réellement désactivé leurs extensions, ce qui a donné lieu à des visites des bots d’Open Site Explorer et Yandex.
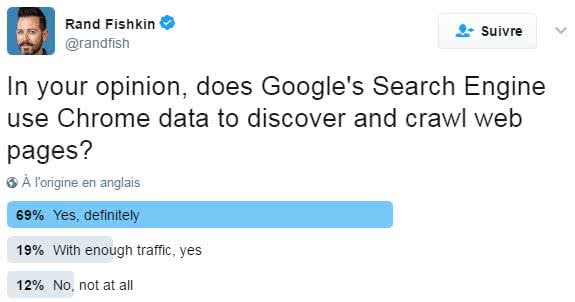
Rand Fishkin de Moz a publié un sondage sur Twitter pour connaître l’opinion des utilisateurs quant à l’utilisation des données Chrome comme crawler. Le résultat est sans appel, 88% des utilisateurs croient que Google crawle de nouvelles URL à partir des données Chrome, et 69 % d’entre eux sont sûrs qu’il le fait de façon systématique.
En conclusion :
Etant donné le périmètre important de la galaxie Google et les temps de latence entre la mise en route de projets et la visibilité dans les moteurs de recherche, les paramètres de l’étude proposée par le cabinet Stone Temple Consulting semblent assez minces.
Le test effectué, les quatre pages orphelines, la période de 2 semaines au plus, et le nombre d’utilisateurs sollicités est peu révélateur de l’interaction entre Chrome et Googlebot. Surprenant, donc, de la part de Google d’affirmer se priver d’une quantité d’informations aussi importante lorsque l’on considère leur objectif principal de navigation et rendu de l’information optimal pour l’utilisateur.