
Logs + crawl : Guide ultime de l’analyse croisée
Ecrit par Mathieu CHAPON
le
Ce guide aura pour objectif de vulgariser ce type d’analyse très riche d’enseignement concernant le comportement d’un moteur de recherche sur un site. Nous l’appelons communément, l’analyse croisée logs+crawl.
Ce type d’audit est souvent réalisé par des référenceurs expérimentés qui nécessitent une bonne connaissance des comportements des moteurs de recherche et une approche technique du SEO.
Elle est souvent jugée complexe (et c’est parfois le cas sur de grosses volumétries) et est aujourd’hui accessible au plus grand nombre grâce à la pléthore d’outils proposée. Cela nécessite forcement de s’équiper d’outil payant ou gratuit surtout si vous avez de la volumétrie et que vous souhaitez obtenir des graphiques macro de vos données. L’historisation des logs serveur est souvent utile pour comprendre les phénomènes d’indexation par exemple ou encore pour déterminer les fenêtres de crawl (durée du crawl de Google pour voir la majorité de vos pages).
L’objectif de ce guide, qui se veut complet mais pas exhaustif, est d’être très opérationnel avec un peu de concept et de théories pour comprendre l’intérêt de mettre les mains (un peu ou beaucoup en fonction des solutions que vous choisirez) dans le cœur de la « matrice ».
Ces outils d’analyse de la crawlabilité d’un site n’ont qu’un seul rôle : valider vos hypothèses, évaluer la volumétrie d’un problème, mesurer des taux de crawl ou de pages actives, etc. Vous ne pourrez pas améliorer vos performances SEO si vous n’êtes pas capables d’en interpréter les résultats. Pire, il est courant de voir des référenceurs prendre les mauvaises décisions sans se rendre compte qu’en réalité, le crawl ou les logs sont incomplets (qui est une erreur très courante).
Nous le disons souvent à nos clients (et nos jeunes recrus), l’outil n’est pas une fin en soi, il vient simplement confirmer ce que vous présentez dans votre travail d’analyse préalable. Ces outils ne remplaceront pas votre flair, votre analyse onsite, la concordance d’une date de MAJ de Google et la baisse du trafic, l’analyse des données analytiques, etc.
En fonction des outils que vous utiliserez, il sera parfois nécessaire d’utiliser des lignes de commandes pour lancer le crawl (en python par exemple) ou pour filtrer vos logs, particulièrement si vous travaillez sur des fortes volumétries. Néanmoins, avec des outils payant comme Oncrawl ou Botify, le lancement de ce type d’étude nécessite moins de compétences techniques. Par contre, les résultats obtenus nécessitent une bonne maitrise des indicateurs et de l’expérience pour en interpréter correctement les résultats.
Aussi, Search Foresight s’est donné comme objectif de publier un guide complet, présentant ce qu’est une analyse croisée, qu’elles sont les résultats utiles à exploiter en passant par l’installation d’outil open source ou payant. Bref, un tour d’horizon de cette pratique du SEO qui peut être redoutable dans les chantiers de croissance découverts et dans le dressage des bots sur vos sites web.
L’histoire de l’analyse de logs
Aujourd’hui, ce type d’approche est de plus en plus souvent proposée par des agences ou des consultants en particulier avec des services SAAS comme Botify ou Oncrawl. Aussi, la première agence seo en France à avoir développé ce type d’approche a été Aposition. D’ailleurs, une partie des anciens salariés qui ont lancé aujourd’hui ces solutions en Saas sont originaires de cette agence : Botify, KELOGS, WatussiBox, …
Philippe Yonnet et moi-même l’avons bien connu pour y avoir été salariés pendant plusieurs années, sur les dernières années « fast ». Elle a existé pendant 10 ans (de 2002 à 2012) et y a développé ses propres outils qui s’utilisaient en général en ligne de commande. Elle avait ainsi acquis une réputation d’agence SEO technique qui était reconnue par tous les experts dans le domaine.
Aujourd’hui, plusieurs solutions sont à votre disposition et nous allons les aborder dans ce guide:
- Solution « à la main » : Excel (avec Macro) et ligne de commande qui a l’avantage de ne rien couter « financièrement parlant », mais qui peut vous prendre énormément de temps si vous n’automatiser pas vos tâches.
- Solutions Opensource : ELK (Elasticsearch, Logstash & Kibana), Watussibox en version « open-source », solutions peu coûteuses, mais nécessitant des compétences en développement et Linux.
- Solutions payantes : Botify, Oncrawl, Kelogs, DeepCrawl, Screaming Frogs (version moins aboutie), etc. qui sont des services permettant de vous mettre à disposition une solution « all inclusive » : Installation ou Saas, récupération de vos logs et traitement de ces derniers, interfaces graphiques, formations à leurs outils, historisations des données. Les coûts sont importants mais les investissements financiers sur l’optimisation SEO aussi. Il devient primordial de pouvoir mesurer l’efficacité des actions par des outils de ce type.
Il faut comparer vos besoins et votre capacité de faire pour choisir la meilleure de ces solutions ! Nous aborderons dans une seconde partie, la mise en place des solutions « à la main » et « Opensource ».
Monitoring de logs et Analyse croisée
Il est nécessaire de distinguer le monitoring (suivis des logs) de l’analyse croisée qui inclut le crawl de votre site avec un crawleur reproduisant le passage d’un bot. En effet, nous ne sommes pas sur les mêmes types d’analyse :

L’analyse croisée : Logs + Crawl
L’analyse croisée que nous appelons Audit approfondi chez Search Foresight permet de superposer deux calques :
- l’un concernant le passage des bots sur le site avec les contraintes qu’ils subissent : performance des serveurs, profondeur, fraîcheur, budget de crawl, Page rank interne, etc.
- l’autre s’obtient avec un crawleur reproduisant le passage d’un bot sans les contraintes citées au-dessus et permettant ainsi d’obtenir un inventaire exhaustif de toutes les urls accessibles qu’un moteur de recherche peut potentiellement récupérer.
Ainsi, en comparant les deux calques, vous mettez en lumière les zones où Googlebot crawle et ne crawle pas. Surtout, vous pouvez faire le constat de ce qu’il crawle alors qu’il ne devrait pas le voir (spider trap et pages orphelines que nous aborderons un peu plus loin dans ce guide) et au contraire, les pages que ne voient pas ou peu les moteurs de recherche, alors qu’elles sont stratégiques pour le site.
Le monitoring de logs

Le monitoring de logs est intéressant en se faisant sur la durée en analysant, à une fréquence quotidienne, les « hits » (visites) des bots ainsi que les visites des internautes en provenance des moteurs sur son site. Les premiers indicateurs suivis sont en général, le taux de crawl, le taux de pages actives, les codes réponses (3xx, 4xx, 5xx). On peut aller plus loin en mesurant par exemple la fenêtre de crawl qui vous fera prendre conscience de la capacité d’un moteur de recherche à crawler l’intégralité d’un site. Cela permet enfin de mesurer l’impact de ces évolutions entreprises sur son site pour en mesurer l’impact sur le crawl des bots.
La catégorisation de vos urls
Que ce soit pour le monitoring de vos logs ou l’analyse croisée, pour obtenir une vision précise par template de page ou par univers, vous aurez besoin de catégoriser vos pages, en général, en passant par les pattern d’urls à l’aide d’expressions régulières plus ou moins complexes en fonction de degré de précision souhaitée.
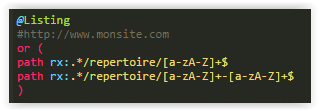
Vous obtenez ainsi des graphiques par type de pages que vous aurez en amont choisi d’identifier pour être capable d’étudier sur ces typologies de page
Qu’est-ce que les logs serveurs?
Les logs serveur enregistrent tout passage d’un humain ou d’un moteur sur votre site.
Attention, selon la cour d’appel de Paris, les entreprises sont tenues, comme les FAI, de stocker les données de connexions de leurs employés et de les communiquer sur réquisition judiciaire, sur une période d’au moins 1 an Voir le décret
Ainsi, vous êtes capables de voir le passage des robots d’indexation (Glop J), les robots des outils SEO (glop J), les robots de spam (pas glop L), les personnes qui essayent de vous faire des injections SQL (pas glop du tout L),etc. Les logs serveur sont fonction du langage de votre serveur. Les plus courants sont Apaches qui respectent en général un format standard et IIS qui est en général au format plus exotique car souvent, manipuler par les équipes de l’infra.
Sans une solution payante, vous êtes souvent amené à devoir retrouver le format de vos logs soit dans la récupération qui est faite par le serveur, soit en ligne de commande pour repositionner vos informations dans les bonnes colonnes.
Si l’on prend l’exemple d’un format de logs Apache standard, voici ce que l’on attend comme information :
217.89.107.37 – [29/Jul/2016:00:00:08 +0200] « GET /detail-vente-edaa74b2-99d8-93ae-4fa7-dbcae055130c.htm HTTP/1.1 » 410 7101 « – » « Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) »
- La Date et l’heure
- L’IP du remote Client
- Le Referer
- L’User-Agent
- URI Query complète (ce champ doit contenir tous les paramètres en méthode GET)
Attention : l’URI Query doit être celle qui est appelée par le « remote client » et non celle réellement appelée par le serveur en cas de réécriture d’url.
- HTTP Serveur Response : la méthode HTTP n’est pas facultative (GET / POST / HEAD / OPTIONS / …) elle permet de détecter comment Google et Bing par exemple considère une partie du site.
- Content Length : le Content Length permet de détecter de façon automatique le surpoids de pages. Cette information nous permet de comprendre les éventuels problèmes de lenteur de Crawl.
- Request Domain : dans certains cas, les URLs demandées ne le sont pas sur le domaine principal (ils le sont sur un sous-domaine, une adresse IP ou un domaine sans les www).
Nous verrons dans la prochaine partie, comment installer des analyseurs de logs en version « à la main », « open source » et payant.
15 ans d’analyse de logs : voici mes enseignements
L’analyse de logs est une analyse encore méconnue ou peu utilisée par les SEO. Pourtant, elle vous offre une vision complète de l’exploration de votre site par le moteur de recherche. Voici mes 15 enseignements après 15 ans d’expériences !
1) Supprimer les pages orphelines (pages détachées de la structure) n’améliore pas le budget de crawl et ne permet pas de rediriger Googlebot vers vos pages stratégiques. Le temps de chargement, la MAJ de la page, le PR interne ou externe sont les KPIS qui favorisent le crawl d’une page.
2) Une balise noindex sur la pagination ou une balise canonical vers la première page de liste flingue le crawl des produits/annonces qui y sont listés. Autrement dit, avec ces balises, vous limitez le crawl de vos pages produits/annonces.
3) Le temps de chargement html que vous pouvez observer sur la search console influence le crawl de Googlebot sur votre site. Chaque site à un temps limité pour crawler un site (budget de crawl) et plus votre site sera rapide, plus Google pourra crawler davantage de pages dans le temps imparti.
4) 301 vs 404 : Je préfère 100 fois supprimer une page avec un code réponse 404 qu’avec une redirection 301. On est d’accord, si la page génère encore du trafic ou obtient de la popularité de l’extérieur, je fais une redirection. Prenant l’exemple d’un site E-commerce, ayant un catalogue produit qui change, à chaque saison, les 301 en masse consommeront 50% du crawl, plusieurs mois après le plan de redirection. Les 404 permettent de limiter le (re)crawl “inutile” de GG.
5) Les sitemaps influencent négativement votre analyse. On peut conclure qu’un site soit très bien crawlé par Google, mais les sitemaps peuvent expliquer ce taux. Bien qu’un site puisse avoir un crawl boosté par les sitemaps.xml, ce n’est pas une garantie de positionnement pour les pages.
6) Google cherche en permanence à reconstruire des urls en utilisant des morceaux de script ou des paramètres pour voir s’il y a un contenu utile à indexer. Résultats, cela peut devenir de vrais spidertraps.
7) 404/410 : aucune différence dans le crawl
8) Le Disallow : /pattern bloque bien le crawl de tous les bots sauf mediapartners-Google. Si vous voyez votre url indexée, soit elle a été indexée avant votre blocage dans le robots.txt soit Google à indexé l’url mais pas son contenu.
9) Sans sitemap pour tout fausser, une page à 4 clics de la HP à 1 chance sur 5 d’être vue par Google. Arrêtez d’optimiser vos pages si Google ne peut pas les crawler ! Assurez-vous d’abord qu’elle soit située à la bonne profondeur.
10) Une page qui rank est visitée dans les 48 heures qui précèdent. Google doit s’assurer que la page est disponible et présente toujours le même contenu pour garantir la satisfaction des utilisateurs.
11) Avant de faire une analyse de logs, assurez-vous d’avoir récupéré l’ensemble de vos logs. Ils peuvent se situer en partie dans le serveur de cache, serveur de réécriture ou les fronteaux. Vérifier les visites de vos logs depuis Google avec les clics sur la search console. Le chiffre doit être proche.
12) Vous avez obligation de stocker vos logs serveurs, vous-même ou par un prestataire à qui vous confiez la délégation. L’article 6 de la Loi n° 2004-575 du 21 juin 2004 pour la confiance dans l’économie numérique prévoit une durée de 1 an. La Loi n° 2006-64 du 23 janvier 2006 relative à la lutte contre le terrorisme préconise 1 an. La CNIL recommande 6 mois à des fins de contrôle des utilisateurs.
13) Au lendemain d’une migration, les urls orphelines explosent, car ce sont toutes les anciennes urls redirigées qui sont encore crawlées.
14) Google met environ 2 jours pour parser un nouveau site après migration avec la prise en compte du plan de redirection. Vous n’avez qu’une chance de faire bonne impression. Après, vous ramez pour regagner sa confiance !
15) Google utilise une IP américaine la plupart du temps. Avec une détection par IP pour renvoyer vos utilisateurs vers la bonne version linguistique, vous risquez de ne présenter que la version US de votre site au moteur. Google n’aura plus accès à vos autres versions pays ce qui sera dévastateur pour le SEO.