Javascript & SEO : les recommandations de Google évoluent et se clarifient
Ecrit par Mathieu CHAPON
le
Les recommandations de Google à propos de la bonne utilisation des frameworks javascript (Angular, React, Vue…) ont longtemps été inexistantes, et au mieux assez floues. Mais Martin Splitt, webmaster trends analyst chez Google, vient de clarifier ces recommandations, d’abord via une série de videos didactiques sur la chaine Youtube de Google destinée aux webmasters, et ensuite à l’occasion d’une conférence donnée à l’occasion du récent Google I/O avec Zoe Clifford, qui est l’employée de Google à l’origine du projet « Googlebot Evergreen ».
Et ce qui est particulièrement notable, c’est que ces recommandations ont sérieusement évolué… Listons ensemble les principaux enseignements que l’on peut tirer de l’analyse de ces principales videos
Le Dynamic Rendering n’est plus considérée comme une bonne solution à long terme
John Mueller a lontemps préconisé le « Dynamic Rendering » ». Le « Dynamic Rendering » consiste à présenter aux bots des moteurs de recherche une version « normale », c’est à dire dont le HTML est généré côté serveur, et de laisser les utilisateurs bénéficier d’une version dont l’UX est améliorée par l’utilisation intensive du javascript côté client. C’est un message implicite envoyé aux propriétaires de site que l’utilisation de frameworks javascript n’est pas idéal pour assurer un bon référencement de son site et que créer cette version alternative pour les robots était jugée comme une solution plus sûre.
Mais la position exprimée par Martin Splitt montre une évolution : le Dynamic Rendering n’est plus considéré comme une solution valide à long terme. C’est d’ailleurs également la position que nous avons défendue auprès des clients de SF depuis que Google a commencé à parler de Dynamic Rendering. En effet, les frameworks javascript sont des outils, qui comme tous les outils, peuvent être bien utilisés, mais aussi très mal employés. En soi, il est tout à fait possible de développer un site web de façon moderne, en utilisant les frameworks javascripts et les possibilités des browsers modernes sans créer des problèmes pour le référencement. Mais hélas, beaucoup d’implémentations sont catastrophiques. Martin Splitt explique dans ses différentes vidéos comment créer des sites parfaitement référençables avec VueJS, ReactJS ou AngularJS.
Si avoir un bon référencement est crucial pour vous, optez pour le « Server Side Rendering »
Martin Splitt et Zoe Clifford expliquent que Googlebot crawle et indexe le contenu en deux passes : dans un premier temps, Googlebot explore le web pour trouver les liens et indexe le contenu trouvé dans le code HTML téléchargé, mais sans exécuter le javascript. C’est le comportement traditionnel du Bot de Google, connu depuis son lancement en 1998. Le contenu généré côté client en javascript est exécuté ultérieurement dans une deuxième étape, (qui intervient parfois des jours après la première selon les expériences menées chez SF). Cette étape est appelée la phase de « rendition » par Google, et on sait qu’elle est réalisée dorévant via la dernière version de Chromium headless, ce qui était l’une des autres annonces de Google I/O
Pourquoi deux étapes ? En fait, Martin Splitt explique que la phase de rendition est extrêmement coûteuse en ressources informatiques, et beaucoup plus lente que la méthode traditionnelle. Pour continuer à crawler le web rapidement, Google doit utiliser en priorité la méthode traditionnelle, indexe le contenu trouvé ainsi, et ensuite va essayer d’aller chercher le contenu manquant dans le HTML généré dans le navigateur, mais beaucoup moins souvent.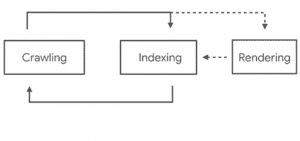
La recommandation de Martin Splitt qui découle de ce comportement est simple : si votre contenu évolue souvent, ou si vous avez un gros site, vous avez besoin que votre contenu soit indexé dès la première passe de Googlebot. Ce qui implique d’utiliser les frameworks javascript pour générer le code HTML intégrant le contenu à faire indexer côté server (c’est ce qu’on appelle dans le jargon développeur le SSR : Server Side Rendering, rendition côté serveur). L’une des façons les plus élégantes de le faire est d’utiliser les possibilités de pré-rendition des frameworks javascript.
La prérendition : une solution efficace pour créer un site codé de façon moderne et rapide à crawler et indexer
La prérendition consiste à placer le code javascript générant le code à faire indexer côté serveur, et d’exécuter le code à l’avance, côté serveur également, pour pré-générer une version du HTML qui sera délivrée ensuite au navigateur (ou à Googlebot). Pour le crawler, le site se comporte comme un site traditionnel fait en PHP ou en Asp.net
Martin Splitt cite différentes solutions pour implémenter une prérendition : Rendertron et Puppeteer et Chromium Headless, ou React Snap pour ReactJS. Mais cette solution ne convient pas à tous les cas de figure : en effet, la rendition est aussi coûteuse pour votre serveur web que pour Googlebot. C’est donc une mauvaise idée de générer une image HTML du contenu à chaque requête du navigateur. Le code pré-rendu doit être généré comme vous le feriez avec un cache HTML (et en réalité : c’est un cache HTML).
Si votre contenu évolue très souvent, le risque est grand que vous envoyiez à vos utilisateurs une version obsolète de votre contenu.
Dans ce cas, vous avez le choix entre deux méthodes :
- le dynamic rendering (mais nous avons vu que ce n’est pas la solution la plus durable et la plus élégante)
- ou le SSR avec une « hydration »
L’hydration : le nouveau concept pour faire de l’hybrid rendering simple et efficace
A cause des limites du prerendering, mais aussi pour offrir une meilleure expérience utilisateur, beaucoup de développeurs finissent aujourd’hui par opter pour une génération du HTML côté navigateur de l’utilisateur. Mais nous l’avons vu, ce n’est pas la solution qui garantit un bon référencement.
Alors, faut-il arbitrer entre la peste et le choléra, ou peut-on avoir le meilleur des deux mondes ? En fait, il est possible d’imaginer des solutions hybrides (ce que l’on appelle « l’hybrid rendering »). Il est par exemple possible de générer côté serveur une partie du code HTML (contenant les balises SEO, le texte, les principales images). Et ensuite un code javascript complétera le contenu côté client pour offrir la meilleure expérience utilisateur possible.
Cette approche dite en « amélioration progressive » est incontestablement la plus élégante. L’une de ses vertus est d’offrir des performances élevées. Mais l’un de ses inconvénients est d’être difficile à coder rapidement. Un autre inconvénient est qu’elle oblige à générer du contenu frais côté serveur, même pour un site dont les pages changent toutes les secondes !
Les différents type d’intégration possibles. La solution avec hydration constitue aujourd’hui le meilleur compromis.
La solution moderne, c’est d’utiliser les possibilités d' »hydration » des frameworks javascripts. Le principe de l’hydration, c’est de générer une première version du HTML en SSR, puis le code javascript côté client modifiera le contenu de la page pour « rafraîchir » le contenu, et donc offrir une meilleure expérience utilisateur. Ce fonctionnement est facilité par les frameworks permettant la création d’un code dit « universel » ou « isomorphe », c’est à dire un code qui peut être utilisé côté serveur comme côté client. C’est ce que permet la version « Universal » d’Angular, mais c’est aussi possible de manière plus native avec Vue.js et et React.
Il existe même des librairies dédiées à l’hydration : Next pour React, et Nuxt pour Vue.js
Une fois de plus, l’hydration peut être la pire et la meilleure des choses : modifier le contenu côté client pour réactualiser le contenu, c’est ok. Mais changer la valeur de certaines balises peut vous conduire à d’énormes problèmes. Par exemple, implémenter une balise robots avec la balise noindex côté serveur, et ensuite faire passer cette valeur à « index » côté client est une idée désastreuse. Elle aura pour conséquence de désindexer la page, la phase de rendition ne sera jamais lancée ! D’une manière générale, nous ne recommandons pas chez SF de modifier de façon importante la structure de la page via l’hydration.
Quelques conseils spécifiques pour les frameworks les plus populaires
Martin Splitt donne également des exemples de code et des conseils pour les frameworks les plus populaires. Voici les informations à retenir selon moi.
Tout d’abord, une erreur souvent commise est de ne pas compléter les balises title et metas SEO correctement avec les frameworks javascript.
Sur Angular, c’est possible en utilisant les services « meta » et « title ». Sur React, grâce au composant Helmet. Et sur Vue, en exploitant l’extension vue-meta. Ces outils permettent de générer des versions dynamiques (calculées) du contenu des metas en fonction du contenu d’autres champs (comme créer une description avec le début du contenu d’un post pour un contenu de type blog). Donc avoir des balises meta uniques et adaptées est possible et facile avec ces frameworks (à condition d’y penser…)
Côté Vue.js, on fera attention à basculer les liens en mode « history API ». Cela permettra de générer des liens crawlables normaux, et non des urls avec des # suivis de paramètres. Googlebot ignore par principe ce qui se trouve derrière les #, du coup un site fait avec les urls par défaut prévues dans Vue n’est pas explorable du tout !
Pour finir, signalons que Googlebot, même en version « evergreen », continue de fonctionner avec une file d’attente d’urls à crawler, ne simule pas de « sessions » et donc oublie à chaque téléchargement de contenu toutes les informations de personnalisation stockées lors de la visite d’une url précédente. C’est vrai pour les cookies, mais aussi pour les service workers et plus généralement toutes les données d’environnement stockées par un utilisateur normal.
Les videos de la série « Javascript SEO »
https://www.youtube.com/playlist?list=PLKoqnv2vTMUPOalM1zuWDP9OQl851WMM9
Plus d’infos sur le dynamic rendering
Learn more about dynamic rendering → https://bit.ly/2Xoh8BN
Get started with Rendertron → https://bit.ly/2TCZU60
Read about dynamic rendering with Rendertron → https://bit.ly/2Xfqe3q
La conférence de Martin Splitt et Zoe Clifford au Google I/O 2019 :
Google Search and JavaScript Sites (Google I/O’19)
https://www.youtube.com/watch?v=Ey0N1Ry0BPM