Une clarification de ce que Google appelle le budget d'exploration
Ecrit par Marc Grosvalet
le
Le 8 décembre dernier, John Mueller avait promis de clarifier la notion de « budget de crawl ». Et c’est chose faite depuis lundi dernier sous la forme d’un billet sur le blog webmasters de Google signé de Gary Illyes.
Google nous a donné sa version du « crawl budget ». Est-ce plus clair pour autant ?
De quoi le « budget de crawl » est-il le nom ?
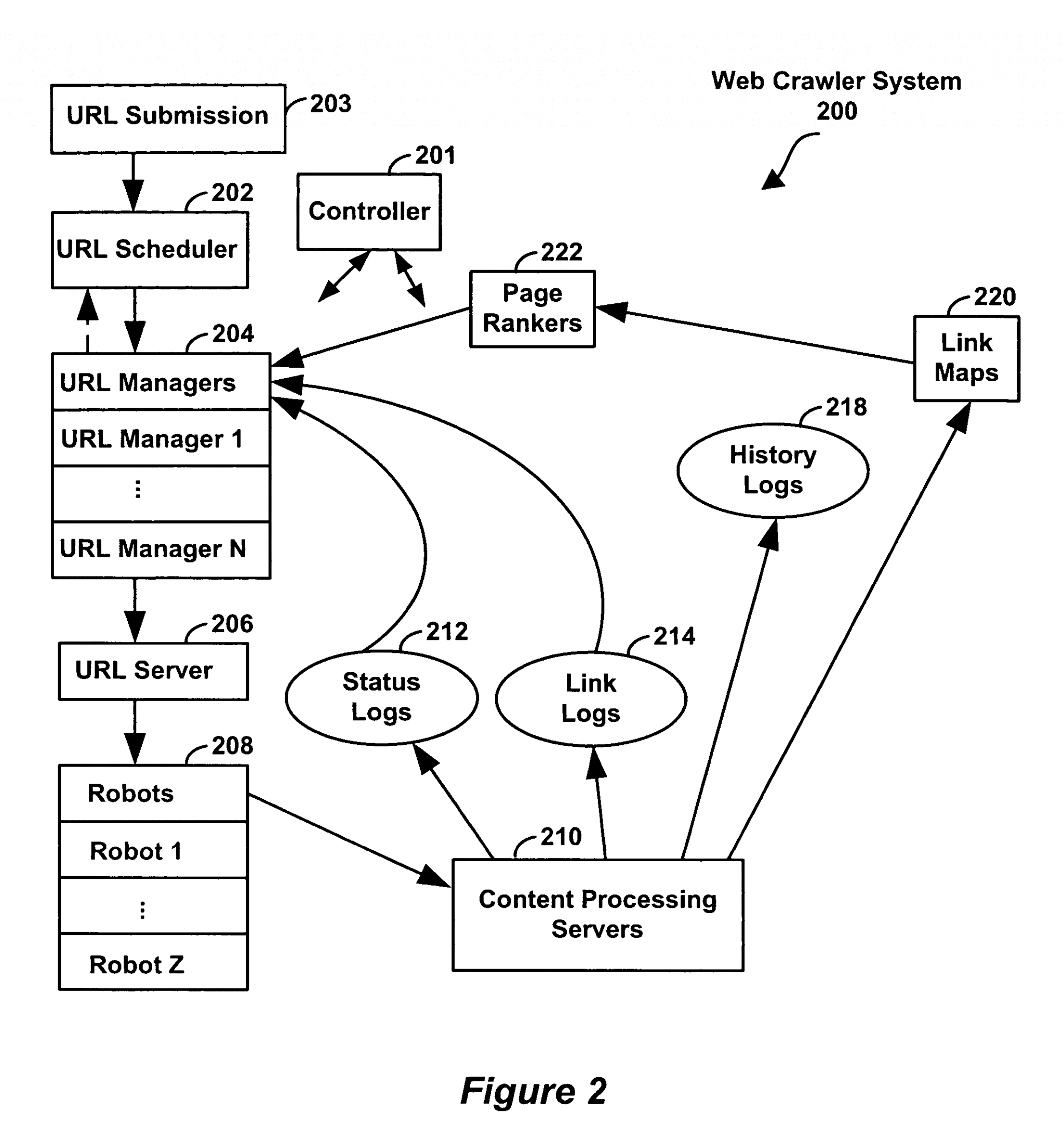
Pour définir le « crawl budget », le billet de Gary Illyes rappelle l’existence de deux comportements fondamentaux de Googlebot :
- Le respect de la « politeness policy »
- La demande de crawl
et l’impact de ces deux comportements influence ce que les webmasters appellent le « crawl budget ».
« En associant la vitesse d’exploration et le besoin d’exploration, nous définissons le budget d’exploration comme le nombre d’URL que Googlebot peut et veut explorer ».
La « politique de politesse » date du tout début des crawlers, dans les années 90. A cette époque, les serveurs étaient lents, la bande passante limitée, et il était facile de faire tomber un serveur avec une cadence de crawl trop élevée. Le principe, même sur des bots modernes, est donc de ne pas « surcharger » les serveurs avec un trop grand nombre de requêtes de bots par seconde, et les limites hautes en terme de consommation de bande passante, même si elles sont considérablement plus élevées aujourd’hui, continuent d’exister.
Aujourd’hui, les bots s’adaptent dynamiquement à la capacité de montée en charge des serveurs (le « host load ») en observant les signaux de « stress » qu’ils renvoient : erreurs 500, lenteurs, time out…
Des serveurs ou des applicatifs lents vont donc ralentir la cadence de crawl observée… Même chose si on change dans la Search Console la limite de cadence de crawl
La « demande de crawl » résulte de l’intérêt que Google porte à vos pages. Et cet intérêt dépend :
- de la popularité de la page
- de la fraîcheur de la page, et son caractère à jour (si ce critère a de l’importance dans le contexte : par exemple des articles d’actualité)
- de l’absence de critères négatifs :
- pages piratées ou comportant des malwares
- pages dupliquées ou vides de contenus
- pièges à robots, provoqués par la navigation à facettes
- un trop grand nombre de soft 404
- un contenu de faible qualité ou pire, « spammy »
L’ensemble de ces critères est géré ensuite par un programme baptisé ordonnanceur (« scheduler » en anglais) qui décide de l’ordre d’appel des urls et de la cadence d’exploration.
Ce que le « crawl budget » n’est pas
Je regrette que Gary Illyes se soit contenté de donner simplement « sa » définition du « crawl budget », sans tordre le cou aux « mythes urbains » sur le sujet. En effet, beaucoup de webmasters ont en tête une définition erronée et simpliste, qui consiste à penser que Google leur alloue un « budget de crawl », par exemple 500 000 urls par mois. Et qu’une fois ce budget défini, il vaut mieux faire crawler à Google des urls utiles que des urls inutiles en bloquant le crawl des deuxièmes pour favoriser les premières. Cette approche avait reçu le nom de « bot herding ».
Il y’a une dizaine d’années, avec l’infrastructure « Big Daddy » de Google et son comportement de crawl par « couches », le comportement du bot était assez figé pour certaines catégories d’urls, et le « bot herding » avait encore du sens. Mais depuis la mise en place d’infrastructure « Caffeine », le comportement de crawl de Google est devenu plus sophistiqué et n’est plus influencé que par le « crawl demand » et le « crawl rate », tel que Gary Illyes décrit dans son billet de blog.

En clair, pour inciter Google à crawler plus d’urls d’un certain type, la solution ce n’est certainement pas parce qu’on l’empêche d’aller voir ailleurs. Cela ne fonctionne plus (et cela a toujours mal fonctionné). Il faut changer la valeur des signaux renvoyés par vos pages.
Il est intéressant d’améliorer les critères de chaque page, mais aussi d’un groupe de pages si l’analyse des logs montre qu’elles sont négligées par Googlebot. En effet, Google teste ce qu’il appelle des « buckets » d’urls, des groupes d’urls appartenant au même répertoire virtuel ou partageant la même racine. Si un bucket présente des problèmes de qualité, l’ordonnanceur (le « scheduler ») va déprioriser l’exploration de cette zone, qui sera donc dans le meilleur des cas crawlée moins souvent, et au pire, crawlée de façon incomplète.
Bref, pas sûr que l’initiative de Gary Illyes ait mis un terme à la confusion régnant sur le crawl budget. Mais au moins, cela a rappelé aux webmasters les vrais comportements à l’oeuvre derrière les variations de comportement de crawl de Googlebot. Et en soi, c’est déjà beaucoup. Merci Gary.
Pour en savoir plus : Le billet de blog sur le « Crawl Budget »