Quelle influence l'attribut noindex a-t-il sur le crawl ?
Ecrit par Mathieu CHAPON
le
John Mueller l’a rappelé il y’a quelques jours : ce n’est pas une bonne idée d’alterner entre noindex et index dans vos balises meta robots.
C’est pourtant ce que font certains sites marchands de manière habituelle : dès que le produit n’est plus en stock, les pages passent en « noindex », et reviennent en « index » dès que le marchand est à nouveau approvisionné.
C’est une pratique qui peut nuire au bon référencement des pages produits.
Mais d’où vient cette recommandation ? Quel est véritablement le problème ?
Basculer une page en noindex changera à terme la manière dont elle est crawlée
Si vous ajoutez dans l’attribut content de la balise meta robots la valeur « noindex », Google va logiquement décider de ne pas indexer ce contenu.
Mais dans une logique propre à Google, le moteur considère que cela signifie que crawler cette page ne sert à rien, puisqu’il ne pourra pas en exploiter le contenu.
Une page en « noindex » reste crawlée normalement un moment, puis le rythme de recrawl de cette url diminue.
Les liens figurant sur une page en noindex finissent aussi par ne plus être crawlés !
Ce point avait été confirmé par John Mueller il y’a quelques mois : s’il voit une valeur « noindex,follow » ou juste « noindex » dans une balise meta robots, Googlebot finit par se comporter au bout de quelques semaines comme si cette balise contenait « noindex,nofollow ».
Nous avions évoqué ce sujet dans un article en janvier dernier :
À long terme, les liens présents dans des pages en noindex ne sont plus suivis !
La conséquence : si vous changez l’indexabilité de vos pages très souvent, votre référencement sera mauvais
John Mueller l’a rappelé récemment sur Twitter : passer trop souvent les valeurs de « noindex » à « index » puis l’inverse est une mauvaise idée.
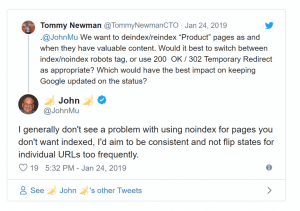
Pourquoi ?
Tout simplement parce que si Googlebot a repéré la balise noindex et crawle la page moins souvent, ainsi que les liens figurant sur cette page, trois « effets de bord » peuvent apparaître :
- Googlebot peut ne pas s’apercevoir que la page est revenue en statut « index » entre deux passages ! Une page que l’on veut voir indexer ne le sera finalement pas, et évidemment, cette page indexable ne générera pas de trafic SEO
- Googlebot ne crawlera pas l’environnement de ces pages normalement. Cela a des conséquences sur la circulation du pagerank, la vitesse de découverte des nouveaux liens
- D’autres effets de bord sont possibles : pages en index qui continuent de ne pas être considérées comme prioritaires pour le recrawl, signaux (scores de la page dans l’algorithme) dégradés par rapport à ce qu’ils auraient été si la page était resté indexable tout le temps

Finalement, quelle est la bonne reco ?
D’une manière générale, il faut se dire qu’il y’a une réelle inertie dans la prise en compte des changements impactant le maillage interne et des balises pilotant l’indexation et le crawl.
Désindexer une page pour la rendre indexable à nouveau quelques heures / jours après est une mauvaise idée. Par exemple, si un produit n’est plus en stock, il vaut mieux laisser la page indexable et indiquer clairement que le produit n’est temporairement plus disponible.
Si par contre le produit sort définitivement du catalogue, désindexer la page a plus de sens. Mais d’autres mesures sont possibles, comme rediriger l’url sur un produit équivalent, ou renvoyer une erreur 404 !