Googlebot bientôt sur Chrome 59 : quels impacts ?
Ecrit par Mathieu CHAPON
le
Au Searchmetrics Summit 2017, Bartosz Goralewicz de l’agence polonaise Elephate a présenté plusieurs points techniques issus de ses tests relatifs au crawl du JavaScript par Google, et ses interrogations des gens très au fait sur le sujet comme Ilya Grigorik.
Sa grande problématique est de comprendre comment est crawlé un site en JS par Google, si l’ensemble des pages sont bien parcourues. Ses conclusions sont évidemment que non. Le HTML, même mal codé, est parfaitement compris. Le JavaScript, au contraire, a besoin d’être irréprochable pour garantir un crawl optimal, et donc une indexation de toutes vos URLs.
Le bot de Google a un « budget » de crawl limité pour chaque site : trop de JavaScript à charger et exécuter lui donnera trop de travail, moins de pages seront donc crawlées.
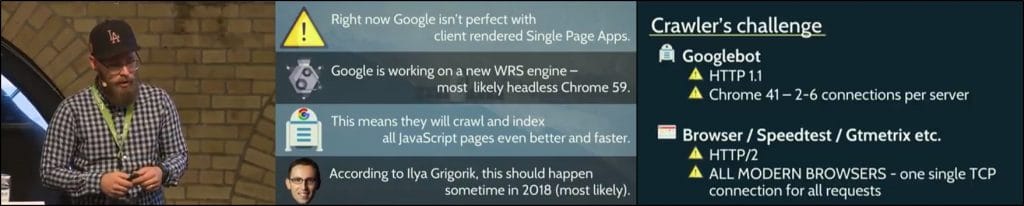
L’étude va davantage dans le détail : le bot de Google se sert du navigateur Chrome 41 pour son moteur de rendu (Web Rendering Service), qui date de mars 2015. Pour visualiser une page (exécuter son JavaScript), la technologie utilisée est SPDY qui ne gère que le HTTP 1.1 et de 2 à 6 connexions simultanées par serveur. A titre de comparaison, les navigateurs actuels et outils de webperformances courants gèrent le HTTP2 et une seule connexion TCP par serveur.
La grande révélation de ses recherches est d’avoir fait dire à Ilya Grigorik que Google travaille sur une mise à jour du Web Rendering Service, qui serait basé sur Chrome 59, donc davantage capable d’exécuter le JavaScript pour le crawler et indexer les pages (nous sommes à la version 63 de Chrome). Et bonne nouvelle, nous aurons la capacité de faire la même chose via l’API Puppeteer développé par leurs soins pour nous permettre de générer un rendu visuel beaucoup plus proche de celui de Googlebot.
Ce serait pour cette année 2018.
A l’heure actuelle, afin de générer un rendu visuel proche de celui du Googlebot, on se sert d’outils utilisant la technologie Phantom JS. Malheureusement, cette méthode n’est pas toujours fiable.
Démonstration : une même page,
- vue dans le navigateur Firefox
- dans la Search Console (Explorer comme Google)
- par le crawler Screaming Frog.
Un widget d’abonnement à la newsletter n’est pas du tout vu par Googlebot, mais bien présent pour Screaming Frog. Le risque de mauvaise interprétation est donc réel.
