Googlebot Evergreen : Googlebot utilise dorénavant la dernière version de Chrome
Ecrit par Mathieu CHAPON
le
A l’occasion du récent événement Google I/O, Google a annoncé que son bot explorait dorénavant le web en utilisant la dernière version de Chrome. En clair, Googlebot se comporte maintenant comme un Chrome version 74, et non 41 !
Mais qu’est-ce que cela change concrètement ?

Googlebot passe en mode « evergreen »
Lorsque Google a révélé que Googlebot était capable d’exécuter le javascript pour indexer les contenus générés côté navigateur, ils avaient également précisé que cette version de leur crawler tournait sur Chrome 41. A l’époque, cette version du navigateur était déjà obsolète. Mais c’était un premier pas, et Martin Splitt, l’un des ingénieurs travaillant sur le crawler avait expliqué il y’a déjà de nombreux qu’ils travaillaient à une nouvelle version « evergreen ».
« evergreen », c’est l’adjectif imagé pour décrire les processus ou les logiciels qui ne deviennent jamais obsolètes. En fait, l’idée de départ était d’exploiter les fonctionnalités « headless » incluses dans les versions récentes de Chromium, et donc de remplacer l’ancien Googlebot par Chromium. Cela permet de mettre à jour Googlebot au fur et à mesure du déploiement des nouvelles versions de Chromium, et donc de faire reposer sur la communauté de développement Chromium le soin de mettre à jour … Googlebot.
Cette version avancée du crawler n’est pas utilisée à chaque fois, le crawl se passe toujours en deux temps
Martin Splitt a rappelé à l’occasion de cette annonce que le crawl de Google se passe toujours en deux temps : le code est crawlé une première fois, sans exécuter le javascript. Et c’est seulement dans un deuxième temps que le crawler capable d’exécuter le javascript explorera la page.
Martin Split a expliqué qu’ils travaillaient sur un processus qui fonctionnerait en une passe au lieu de deux. Il n’a donné aucune précision sur la date à laquelle cette nouvelle architecture de crawl serait mise en place.
Le User Agent n’a pas (encore) changé, et c’est volontaire
Google n’a pas encore changé le User Agent de cette nouvelle version de Googlebot, donc même si vous voyez ceci dans vos logs, en réalité c’est une version Chrome 74 qui est en fait utilisée. Pourquoi cet « oubli » ? En fait c’est volontaire, car certains scripts qui détectent les bots des moteurs de recherche devront être mis à jour, et Google veut donner du temps aux développeurs pour corriger leur code. Martin Split prépare un billet de blog pour expliquer comment le faire.
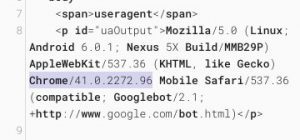
Le « vieux » Googlebot est toujours utilisé dans certains outils
Attention, les renditions obtenues dans la Google Search Console, ou l’outil de compatilité mobile, continuent d’utiliser l’ancienne version de Googlebot, qui se comporte comme un Chrome 41.
Néanmoins, il est facile dorénavant de tester ce que voit le Googlebot actuel en utilisant Chromium en mode « headless browser » à l’aide d’instruction entrées dans la console en mode « ligne de commandes ». On peut également utiliser le couple « Puppeteer / Chromium » pour créer des scripts plus complexes.
Puppeteer est un excellent outil pour piloter la version « headless » de Chrome (surnommée « Chromeless »).
Qu’est-ce que cela change ?
Dès lors que Googlebot exploite la dernière version de Chromium, cela signifie que de nombreuses fonctionnalités avancées des browsers sont dorénavant compatibles avec Googlebot, et peuvent être exploitées. Voici ci-dessous la liste des fonctionnalités non supportées dans Chrome 41 et qui deviennent supportées par la nouvelle version de Googlebot.

Est-ce que cela veut dire que je peux me lâcher et faire un site en full javascript ou en mode SPA et avoir un bon référencement ?
Même si le Googlebot Evergreen annonce un meilleur support des fonctionnalités avancées des browsers, notamment en ce qui concerne le support avancé du Javascript, cette nouvelle version doit respecter les mêmes contraintes que l’ancienne, et rien ne change concernant les recommandations :
- le « Server Side Rendering » reste la solution la plus sûre pour créer un site facile à crawler et à comprendre par un moteur de recherche
- le « Client Side Rendering » pose toujours des problèmes, surtout si le code est lent à s’exécuter, bogué, ou si les actions pour générer le contenu sont peu susceptibles d’être comprises par un bot
- le Dynamic Rendering est la solution préconisée par Google
- Mais un « hybrid rendering » bien fait est plus facile à maintenir, et donne d’excellents résultats.
- Voici un rappel des articles déjà rédigés sur le sujet :
- https://www.search-foresight.com/john-mueller-recommande-le-dynamic-rendering-chez-search-foresight-on-napprouve-pas/
- https://www.search-foresight.com/google-explique-comment-implementer-le-dynamic-rendering/