Google est-il devenu "addict" aux données structurées ?
Ecrit par Mathieu CHAPON
le
Le 26 octobre dernier, Gary Illyes a déclaré au SMX East « qu’il voulait vivre dans un monde où les données structurées seraient moins importantes que maintenant ». Et appelé de ses voeux une évolution où Google serait capable d’extraire des informations de pages web sans avoir à recourir au balisage Schema.org
La montée en puissance des données structurées
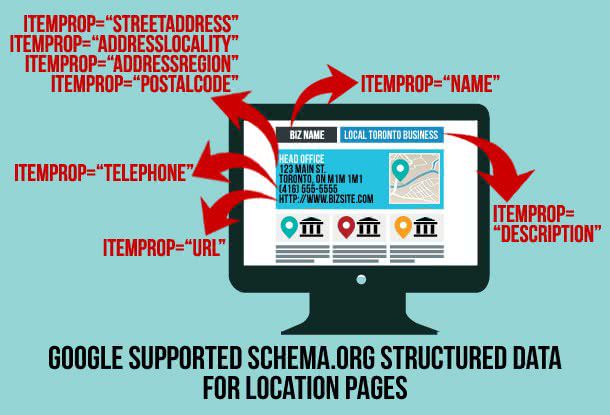
Aujourd’hui, les pages d’un moteur comme Google sont remplies de « rich snippets », de « rich cards », de blocs et de carroussels qui ne pourraient pas exister sans données structurées.
Google est devenu dépendant aux données structurées
Mais du coup, Google est confronté à trois problèmes :
– le spam : les moins scrupuleux des webmasters ont compris qu’en falsifiant les données structurées présents sur leurs pages, ils pouvaient améliorer leur visibilité à moindre coût
– les erreurs de balisage : ajouter des données structurées à son code demande de la rigueur et des ressources techniques. A la fin, les balises ne sont pas toujours lisibles parce que mal implémentées, ou leur contenu erroné
– et le niveau de couverture : même si de plus en plus d’éditeurs de sites ajoutent des données structurées sur leurs pages, souvent pour être « aussi visibles que les concurrents », un nombre considérable de pages webs qui mériteraient d’être taggées, ne le sont pas !
Google va avoir besoin d’une cure de désintox
En vingt ans d’histoire, les moteurs de recherche ont appris (souvent à leurs dépens) que dépendre des informations communiquées par les webmasters pour les fonctionnalités d’un moteur de recherche. C’est ce qui explique aujourd’hui que la balise « meta keywords » ne soit plus exploitée par les grands moteurs de recherche : rapidement spammé, peu fiable, exploiter le contenu de cette balise s’est vite avéré contre-productif.
Dans ce contexte, on peut comprendre que Gary Illyes (qui exprime probablement une opinion partagée par pas mal de monde au sein de la firme de Mountain View) s’inquiète de la situation, et voudrait que Google améliore sa capacité à extraire de l’information sans données structurées. Adieu les problèmes de couverture, les données spammées, les balises illisibles !
Sauf que ce n’est pas pour demain…
Je suis sûr que des gens chez Google travaillent d’arrache-pied pour sortir le moteur de son addiction aux données schema.org, mais pour le moment, le moteur a encore besoin de sa dose, et même d’une dose de plus en forte avec le temps qui passe…
En attendant, Google a besoin de toujours plus de données structurées…
Le fait que Google annonce qu’en 2018, il y’aura encore plus de fonctionnalités à base de balises schema.org, et qu’il faut donc se concentrer sur la mise en place de ce balisage si on est un éditeur de site, n’est pas du tout surprenant. C’est cohérent avec sa stratégie du « mobile first » car les carrousel et les rich cards améliorent l’expérience de recherche sur mobile. Et le futur de la recherche a besoin de données structurées : par de recherche prédictive sur Google Now sans ça, pas de recherche conversationnelle sur Google Assistant sans ça, pas de résultats vocalisés sur Voice Search ou Google Home sans données structurées.
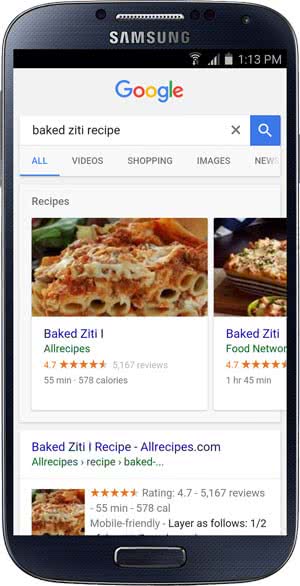
Conclusion : oui, il faut s’intéresser aux données structurées maintenant
Donc, en 2018, prévoyez de la bande passante pour implémenter les balisages schema.org utiles sur votre site. Vous êtes prévenus !