C'est à vous de définir le "chemin" de l'utilisateur !
Ecrit par Mathieu CHAPON
le
Cela va même plus loin : cette pratique est à déconseiller. Pourquoi ? Détaillons un peu plus le problème pour comprendre…
Les composants d’une bonne url
- l’url doit correspondre à une seule page (une seule ressource en général), et une ressource ne doit correspondre qu’à une seule url.
- Le comportement de crawl de Google est lié aux motifs (patterns) d’urls, qu’il cherche à reconnaître. Faciliter la tâche du crawler est une bonne idée. C’est la raison pour laquelle placer toutes les urls à la racine est également déconseillé (c’est-à-dire ce schéma d’url : https://www.domaine.com/le-nom-de-ma-page.html pour toutes les pages)
- l’url doit faciliter également le travail de tracking. L’absence de chemin dans l’url rend le tracking de groupe de pages dans un outil de web analytics moins aisé (il faut recréer ces regroupements dans l’outil, à l’aide d’urls virtuelles ou de rapports dédiés)
- l’url doit être courte, facilement lisible et compréhensible pour des raisons d’expérience utilisateur. Qui plus est, la longueur affichée dans les résultats de recherche est limitée.
- pour le SEO, l’url doit contenir de préférence le ou les mots clés qui correspondent à la requête sur laquelle vous cherchez à optimiser la page. Notons quand même que le poids des mots clés dans les critères de l’algorithme n’est pas considérable, donc cette contrainte n’est pas une nécessité absolue
- pour le SEO également, l’url doit être stable dans le temps. Changer de syntaxe d’urls, c’est prendre le risque que certains signaux soient réinitialisés, bref que l’historique de l’ancienne url soit perdu. Cela nécessite aussi de faire des redirections 301 à chaque fois, ce qui est souvent oublié, mal fait (redirections multiples, production de « soft 404 » etc.)
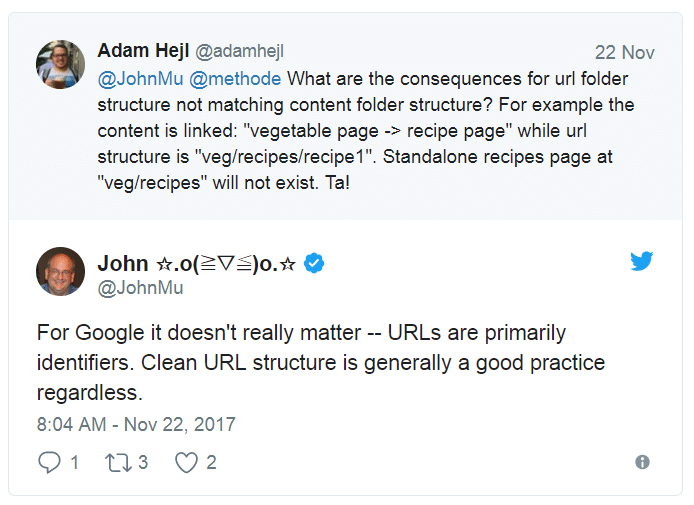
Pourquoi avoir le « path » complet dans l’url est une mauvaise idée ?
En effet, une url avec le path complet ressemble à ceci :
https://www.domaine.com/univers/categorie/sous-categorie/categorie-finale/la-page.html
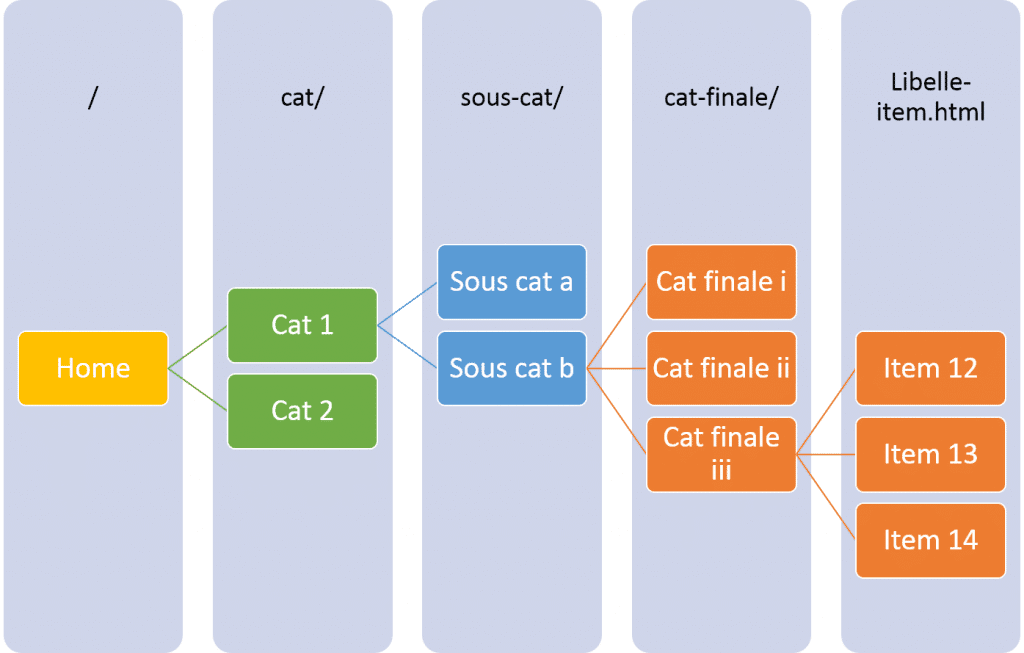
Côté unicité et univocité de l’url il n’est pas rare d’avoir des CMS ou des plateformes web qui permettent d’associer une page à plusieurs catégories. Dans ce cas, si le chemin d’accès est reproduit dans l’url, il existe deux urls désignant la même page :
https://www.domaine.com/univers/categorie/sous-categorie/categorie-finale/la-page.html
https://www.domaine.com/univers/categorie/une-autre-sous-categorie/categorie-finale/la-page.html
Ce qu’il faut éviter à tout prix, car cela crée des doublons parfaits, qu’il faut ensuite chercher à éliminer à l’aide de redirections, de balises canonical, bref tout un travail qu’il est opportun de s’épargner.
La stabilité de l’url n’est pas assurée non plus. Chaque réorganisation du catalogue produit un changement d’url, qu’il s’agisse d’un changement de classement (la catégorie parente change) ou de renommer une catégorie :
ancienne url :https://www.domaine.com/univers/categorie/sous-categorie/categorie-finale/la-page.html
nouvelle url :https://www.domaine.com/univers/nouveau-nom-de-categorie/nouvelle-sous-categorie-de-classement/categorie-finale/la-page.html
Côté longueur et lisibilité de l’url : avoir un chemin complet crée forcément des urls trop longues et peu lisibles.
Quels sont les meilleurs schémas d’urls ?
On peut par exemple décider de créer des urls qui n’incluent que la catégorie finale.
https://www.domaine.com/categorie-finale/la-page.html
En effet, dans la pratique, les catégories finales sont relativement stables dans le temps, et la réorganisation d’un catalogue ou des rubriques entraîne le plus souvent un déplacement de la catégorie finale, plutôt qu’un reclassement dans une autre catégorie finale.
Pour faciliter la création des rapports de tracking, on inclut souvent aussi les catégories racines (les univers) qui sont aussi souvent parmi les composants les plus stables de l’arborescence :
https://www.domaine.com/univers/categorie-finale/la-page.html
Ce schéma d’url est également très lisible pour les crawlers et ordonnanceurs de Google.
A la fin, on a des urls beaucoup plus courtes, qui contiennent les mots clés associés à la page, et à la catégorie parente directe (soit en général uniquement les mots clés pertinents). Et on s’épargne nombre de désagréments générés par des CMS mal fichus.
Euh, mon CMS m’impose d’avoir tout le chemin dans l’url
Hélas, il n’est pas rare que les CMS exigent que le chemin figure dans l’url pour que la bonne ressource soit appelée. En général, cela se manifeste en plus par le besoin d’avoir l’identifiant associé aux catégories dans l’url. Ce qui donne des urls de ce type :
https://www.domaine.com/univers-12/categorie-124/sous-categorie-243/categorie-finale-5379/la-page-produit.html-12479
En pratique, rien n’empêche que le CMS trouve son chemin avec une url raccourcie :
https://www.domaine.com/categorie-finale-5379/la-page-produit.html-12479
ou
https://www.domaine.com/nom-de-categorie-reecrit/la-page-produit.html-12479
Ces urls remplissent les critères mentionnés au début.
Si cela n’est pas possible, regardez si le CMS ne propose pas de créer des alias d’urls ou des « slugs » (des chaines de caractères que vous pouvez définir pour créer une syntaxe alternative).
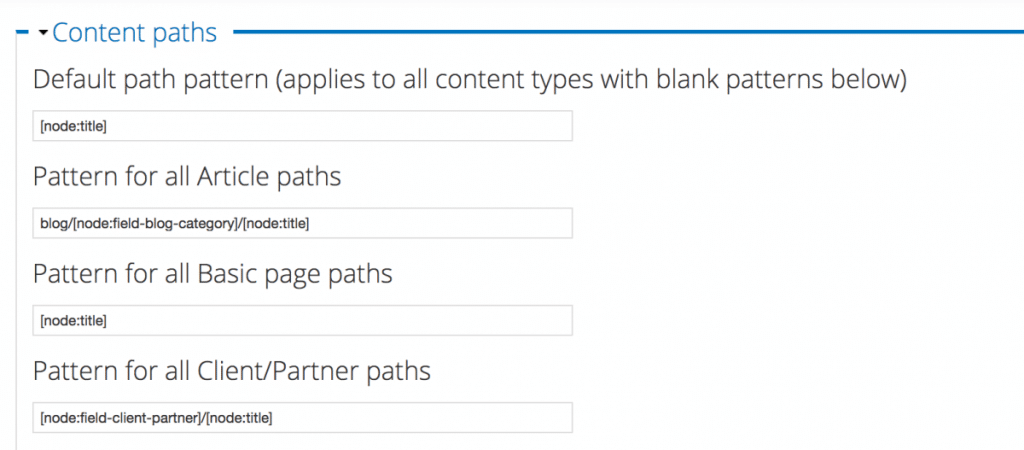
Exemple d’implémentation dans Drupal : les alias d’urls sont entièrement paramétrables à partir des champs disponibles dans le CMS
Dans ce cas, l’url affichée devient par exemple :
https://www.domaine.com/slug-de-la-catégorie/alias-page-produit.html
et le CMS saura « traduire cette url en :
https://www.domaine.com/univers-12/categorie-124/sous-categorie-243/categorie-finale-5379/la-page-produit.html-12479
Si tout cela est impossible : envisagez sérieusement de changer de CMS !
Remarque : le CMS qui s’appuient trop sur le « path » de l’url pour fonctionner ont aussi une tendance fâcheuse à ne pas permettre d’avoir une navigation différente de l’arborescence du catalogue. Or il est important que vous puissiez avoir la souplesse de classer vos items comme vous voulez dans le back-office, et de décider de les afficher comme vous le souhaitez sur votre site internet, y compris en créant des pages affichant plusieurs niveaux de catégories, et de créer des niveaux de menus indépendants des niveaux de catégorisation.
Si ce n’est pas possible : il est encore une fois urgent d’envisager de changer de plateforme ou de CMS
Attention à ne pas réécrire les urls pour le plaisir de les réécrire
L’époque où les bots de moteurs de recherche avaient horreur des urls avec paramètres est bel et bien révolue. Mais elle a produit des réflexes comme l’habitude réécrire entièrement les urls pour faire disparaître les chaines de paramètres. Mais ces soi-disant « Search Engine Friendly » ne sont pas toujours si SEF que cela.
Par exemple, Google comprend mieux les urls suivantes :
https://www.domaine.com/categorie/liste.php?taille=38&matière=laine&couleur=rouge
que
https://www.domaine.com/categorie/laine-rouge-38
surtout s’il existe des pages produit dont la syntaxe est similaire :
https://www.domaine.com/categorie/pull-mohair-12478
Le premier type d’url est moins user friendly, mais moins problématique pour le SEO. Le bot de Google a besoin d’identifier les paramètres dans l’url et leur rôle exact pour bien fonctionner.
L’autre inconvénient de certaines règles de réécriture est de créer des portes grandes ouvertes pour la création de doublons. Les CMS qui exigent un identifiant de ressource dans l’url proposent souvent des règles de réécriture de ce type là :
Exemple d’url brute du CMS :
https://www.domaine.com/index.asp?cat=12434
Url réécrite
https://www.domaine.com/nom-de-la-categorie_12434
Le problème dans ce cas c’est que toutes ces syntaxes erronées appellent la même page qui répond 200 (bref ce sont des doublons)
https://www.domaine.com/nomdelacategorie_12434
https://www.domaine.com/Nom-de-la-Categorie_12434
https://www.domaine.com/autre-nom-de-la-categorie_12434
https://www.domaine.com/nimportekoi_12434
C’est donc une jolie source de doublons accidentels !
Choisissez le pattern d’url qui convient à vos besoins
Si l’on considère les contraintes mentionnées plus haut, on voit qu’elles laissent en fait un champ de liberté assez grand, et qu’il est possible de rendre des arbitrages différents selon ce que l’on veut privilégier. Les contraintes SEO étant en fait les plus faciles à respecter (si, si !), ces arbitrages seront le plus souvent décidés pour favoriser les objectifs marketing (la conversion) ou les contraintes techniques.
Conclusion : réfléchissez bien avant de définir le pattern d’url qui convient à vos besoins, et choisissez le bon, car il doit si possible résister à l’évolution de votre site sans créer des effets de bord…