Schema.org 3.1 et les données structurées : le must have pour votre site web
Ecrit par Marc Grosvalet
le
Le 9 août 2016 schema.org annonçait la nouvelle version des données structurées, ce qui a été reçu avec enthousiasme par la communauté des webmasters, développeurs et référenceurs. Mais, qu’est-ce que le schema.org et ses données structurées ? Pourquoi sont-elles importantes pour le référencement ? Et surtout, en quoi peuvent-elles être utiles pour vos sites Web ?
Premièrement, schema.org est une communauté collaborative de développeurs qui cherchent à développer, standardiser et promouvoir des schémas-types de données structurées. Deuxièmement, définissons ce que sont les données structurées : il s’agit d’un langage de code qui permet de proposer un nombre considérable d’informations aux technologies susceptibles de les lire, notamment les robots des moteurs de recherche. Par exemple, si vous voulez promouvoir un événement sur votre site Web, vous pouvez indiquer, grâce aux données structurées, la date et l’emplacement de cet événement. Ces informations ne seront pas vues par les internautes, mais elles seront lues et interprétées par les robots qui passent sur le site (crawlers). Et cela va générer des « rich snippets », des résultats de recherche « enrichis » avec plus d’informations utiles pour l’internaute.
Ces données structurées peuvent être représentées par différents formats dits “sémantiques” (RDFa, Microdata et JSON-LD) et elles sont soutenues par Google, Microsoft, Yahoo! et Yandex. Ces derniers recommandent de les utiliser (JSON-LD – JavaScript Object Notation for Linked Data – davantage*). Ce soutien résulte du fait que ce langage simplifie grandement le travail de décryptage des informations présentes sur votre site Web. Un robot ne possède pas les mêmes compétences de lecture qu’un humain : l’œil humain communique avec le cerveau pour mettre en relation différentes informations, c’est pourquoi il va logiquement relier une date et un lieu à un événement. Malheureusement, les crawlers ne sont pas aussi développés. Ainsi, les données structurées aident les crawlers à comprendre la relation entre différents éléments (nom de l’événement, date et lieu). Il est donc pertinent de fournir aux moteurs de recherche ces données structurées afin qu’ils puissent nous offrir des résultats de meilleure qualité.
Mais quelle est la genèse de tout ceci ? Les premiers pas des données structurées remontent à 2008. A l’époque, Yahoo! Search Monkey proposait aux développeurs et propriétaires des sites Web d’utiliser des données structurées afin de rendre les résultats de recherche plus utiles et attractifs, et bien évidemment, d’attirer plus de trafic sur leurs sites. Ce service connut sa fin en octobre 2010, résultat d’un accord entre Yahoo! et Microsoft.
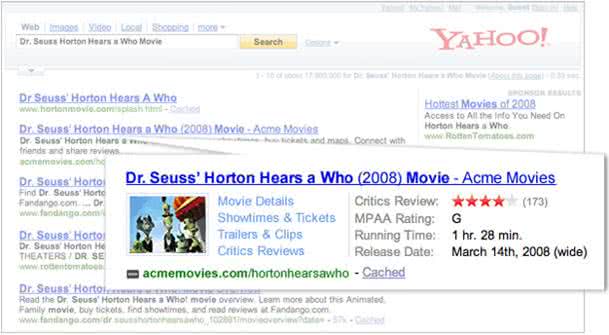
Avant cela, en mai 2009, Google annonçait un nouveau service : les « rich snippets ». Cela répondait au désir de la firme qui déclarait deux ans auparavant vouloir promouvoir la recherche universelle, en mêlant différents types de résultats de recherche (pages de sites Web, images, vidéos…). Ces « rich snippets » affichaient les informations utiles présentes sur les sites Web, autres que la classique méta-description. Par exemple, la note moyenne d’un restaurant, le nombre d’avis des internautes, la fourchette de prix, etc.
 Malgré ces bonnes intentions, peu de webmasters utilisaient alors les données structurées. Les raisons étaient multiples : l’excessive quantité de choix de langages de balisage, la multiplicité des syntaxes (qui provoquait des confusions d’implémentation) et la variation de vocabulaires de balisage (parfois dupliqués, parfois sectorisés). Ainsi, en 2010, moins de 0,5% des sites actifs utilisaient un balisage sémantique.
Malgré ces bonnes intentions, peu de webmasters utilisaient alors les données structurées. Les raisons étaient multiples : l’excessive quantité de choix de langages de balisage, la multiplicité des syntaxes (qui provoquait des confusions d’implémentation) et la variation de vocabulaires de balisage (parfois dupliqués, parfois sectorisés). Ainsi, en 2010, moins de 0,5% des sites actifs utilisaient un balisage sémantique.
Or, cette même année, le HTML 5 fera son apparition et ce sont les micro-données qui seront au cœur de cette mise à jour. De ce fait, la standardisation des données structurées va fortement s’accélérer, et seulement un an plus tard, la communauté Schema.org s’est créée.
Comme nous avons pu le voir précédemment, Schema.org a deux objectifs : standardiser la syntaxe des données structurées (grâce à l’utilisation de deux types de syntaxe, RDFa Lite et JSON-LD – cette dernière étant recommandée par Google), ainsi que normaliser le vocabulaire utilisé (fournir une sémantique universelle). L’exemple suivant explicitera la situation :
Voici un résultat de recherche naturel (SERP) qui utilise des micro-données :

Et les données structurées (en JSON-LD) utilisées pour générer ce type de SERP sont :
<script type= »application/ld+json »>
{
« @context »: « http://schema.org »,
« @type »: « Product »,
« name »: « [product name]« ,
« offers »: {
« @type »: « Offer »,
« price »: « [product sale price]« ,
« priceCurrency »: « [currency in 3 letter ISO 4217 format e.g. USD] »
},
« aggregateRating »: {
« @type »: « AggregateRating »,
« ratingValue »: « [aggregate rating given]« ,
« reviewCount »: « [number of reviews] »
}
}
</script>
Comme nous pouvons l’observer, l’intégration des tags sémantiques permet d’augmenter la qualité de la présentation d’un résultat de recherche dans les SERPs, mais également de :
- Améliorer l’expérience utilisateur : l’internaute en apprend plus sur le contenu de la page ;
- Augmenter le taux de clic (+20 à 30%) : grâce à une meilleure visibilité des articles et pages via l’ajout d’informations complémentaires ;
- Améliorer le positionnement sur les moteurs de recherche grâce à une meilleure compression par les crawlers du contenu de votre site Web.
Ce n’est plus un secret que Google recommande l’utilisation des micro-données (même dans l’optimisation des campagnes Shopping), c’est pour cela qu’il met à disposition de nombreuses informations sur l’intégration des microdonnées, ou sur la vérification de ces données structurées.
Actuellement, le nombre de spécifications de micro-données arrive à plus de 1200 (vs. les 100 catégories de départ) et plus de 10 millions de sites utilisent des micro-données pour améliorer la lecture de leur contenu, leur visibilité et leur taux de clic. Mais les données structurées ne s’arrêtent pas là : elles peuvent être utilisées également dans les emails, Google Now ou encore Pinterest.
Au-delà des résultats enrichis qui sont issus du balisage Schema.org (recettes, concerts, star-rating…), le projet Schema.org pourrait être beaucoup plus ambitieux. En effet, si une part critique des webmasters faisaient le choix de baliser leurs données, ces informations pourraient être utilisées pour alimenter une base d’information colossale (cf. projet « Knowledge Vault »). Ainsi, en s’appuyant sur la force de la communauté, Google pourrait faire passer son Knowledge Graph d’un modèle centralisé (s’appuyant essentiellement sur Wikidata, Wikipedia et quelques sources triées sur le volet) à un modèle décentralisé. Grâce à un tel modèle, Google pourrait construire des réponses qui seraient un agrégat de plusieurs sources, sans qu’on puisse l’attribuer à une source en particulier !
Il ne faut pas pour autant s’alarmer et hurler à la théorie du complot. Cette nouvelle mise à jour du vocabulaire Schema.org peut augmenter grandement les possibilités de spécification du contenu de votre site et ainsi, la capacité des moteurs de recherche à le lire et donc à en extraire les informations pertinentes. Profitez plutôt de cette nouvelle syntaxe qui vous apportera un rendu de meilleure qualité dans les SERPS. Il va de soi que nous vous informerons de son évolution.
*Mise à jour (28/10/2016)
Même s’il était déjà clair pour beaucoup d’entre nous, John Mueller a confirmé dans un hangout que le format préféré de Google quant aux données structurés est le JSON-LD. Il a insisté sur le fait que Google le recommande très fortement, même s’il n’a aucun soucis de lecture du reste des formats. Il a également indiqué qu’il serait possible que des futures données structurées ne soient pris en compte que s’ils sont en format JSON-LD. En résumé, si vos données structurés ne sont pas en JSON-LD, il n’est pas encore nécessaire de les modifier. Nous vous tiendrons au courant si jamais c’est le cas !
Aurora Rivera – @AuroraRiveraSa