Google va changer de méthode pour crawler les urls Ajax !
Ecrit par Mathieu CHAPON
le
Google vient d’annoncer cette semaine qu’il allait arrêter de supporter la méthode proposée en 2009… Est-ce que cela veut dire que tous les éditeurs des sites qui l’utilisaient doivent réécrire le code de leurs pages ? Et bien non…
La méthode des hashbangs en bref
Le nom « hashbang » correspond aux noms des deux caractères #! en anglais US. La méthode proposée par Google en 2009 supposait l’emploi de cette séquence de caractères dans l’URL pour signaler aux crawlers la présence d’une autre version de l’URL, qui elle était crawlable.
Cette méthode était et reste tout à fait opérationnelle, mais elle avait pour inconvénient d’être lourde à déployer. Elle demande en effet de développer deux versions des pages du site : la version « Ajax/Javascript » et la version crawlable.
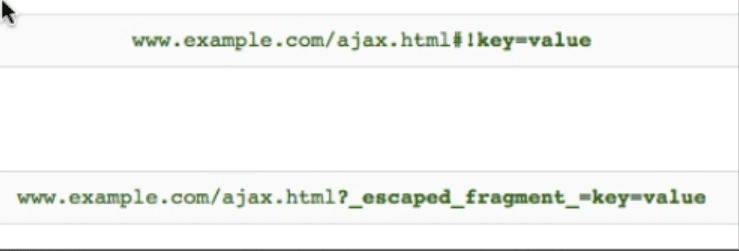
Les deux syntaxes d’URLs dans la méthode des hashbangs : quand la première syntaxe est rencontrée par un crawler, celui-ci appelle la seconde syntaxe en remplaçant #! par ?_escaped_fragment_=. La seconde syntaxe renvoie une page HTML crawlable.
Google a fait d’énormes progrès dans la gestion des pages dont le contenu est généré en javascript.
Depuis 2009, Google a fait d’énormes progrès sur le support du Javascript. Google sait exécuter les scripts en JS, et produire une page identique à celle qu’un utilisateur peut voir dans son navigateur, même si l’essentiel du contenu est généré en Javascript, ou réorganisé par le jeu des CSS.
Ces progrès lui permettent aujourd’hui de pouvoir crawler des pages web partiellement ou entièrement réalisées par du code Javascript, et d’en indexer le contenu. Lorsque ce contenu est créé ou mis à jour de manière asynchrone (en Ajax), il suffit d’utiliser la méthode pushstate() en HTML5 pour modifier l’URL de la page en même temps que le contenu de la page, et cela permet au moteur d’explorer et d’indexer le contenu comme s’il avait affaire à des pages « normales ».
Notons que cette approche, souvent appelée « méthode des pushstate() », permet de ne plus utiliser de syntaxe Ajax dans les URLs : plus de #, plus de #! dans les URLs, mais des URLs « normales ».
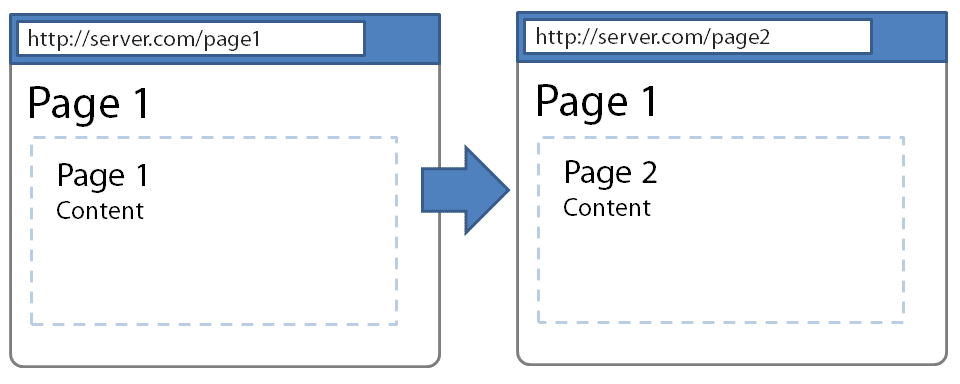
Avec la méthode pushstate() en HTML5, on peut modifier dynamiquement l’URL de la page dans la barre d’URL du navigateur, en même temps que l’on charge un nouveau contenu sur la page. C’est la méthode la plus élégante et recommandée pour rendre l’Ajax crawlable.
Google gérera bientôt les Hashbangs différemment
A partir du deuxième Trimestre de 2018, Google a annoncé qu’il allait cesser de gérer les URLs contenant des « #! » comme avant.
Concrètement, quand le crawler va rencontrer ce type d’urls, il n’ira plus chercher la version alternative : il cherchera à crawler la page en Ajax directement !
Le hashbang prend donc une autre signification : il va permettre à Googlebot de distinguer des pages entières réalisées en Ajax, crawlables comme des pages web classiques, de tous les autres cas où les contenus manipulés en ajax ne créent pas de contenus vraiment assimilables à des pages web.
Le gros avantage de cette nouvelle approche de Google, c’est qu’elle ne demande pas que tous les sites (et ils sont nombreux) qui utilisent la méthode des hashbangs pour rendre leurs pages crawlables, changent leur code.
Enfin en théorie… Car en pratique, il vaut mieux revoir son code pour être certain que Google parviendra à bien crawler ces pages. Ce qui n’est pas garanti à 100%, car on travaille aux limites de ce que sait faire un moteur de recherche.
Les principaux points d’attention selon Google
Google a donné quelques recommandations pour que tout se passe bien suite à ce changement de comportement.
- utiliser la fonctionnalité « fetch & render » de la Search Console pour vérifier que Google est bien en mesure de générer une page qui ressemble à ce que doit voir l’utilisateur et que tout le contenu est bien présent
- utiliser la fonction « inspecter le contenu » de Google Chrome (ou l’équivalent sur un autre navigateur) pour vérifier que les balises HTML utiles pour le SEO sont bien présentes et correctement paramétrées (title, meta descr., canonical, robots, hreflang, next/prev, attributs nofollow).
- vérifier aussi avec la même méthode que les liens sont bien codés avec une balise <a href>

un cas ou la fonctionnalité Fetch & Render montre que la version vue par Google d’une page générée avec le framework ReactJS est très incomplète. Il suffit en effet que certaines ressources soient bloquées (ici des fichiers javascript) pour que le crawl du contenu devienne impossible
Faut-il désactiver la version alternative crawlable ?
Surtout pas pour l’instant : car les URLs en « ?escaped_fragments= » restent indispensables pour les autres moteurs et outils qui suivent cette norme. Cette initiative de Google ne sera pas forcément suivie par les autres acteurs.
Est-ce une bonne ou mauvaise nouvelle ?
C’est plutôt une bonne nouvelle, car pour beaucoup de sites, le changement sera transparent.
Pour d’autres par contre, ce sera moins drôle : des effets de bord sont à attendre en particulier pour les sites qui utilisent des « serveurs de rendition », pour rendre crawlable des sites de type SPA faits avec des frameworks javascript comme AngularJS ou EmberJS. La plupart des implémentations s’appuient en effet sur les hashbangs pour servir une version alternative.
Si c’est votre cas, vous avez trois mois pour faire des tests et réaliser les modifications nécessaires…