Moteur de recherche interne : Lequel choisir ?
Le moteur de recherche interne est un élément capital pour un site web e-commerce. Il permet à l’internaute d’accélérer son accès aux produits ou aux gammes qu’il recherche sans passer par la navigation. Le moteur de recherche peut également être utilisé pour permettre aux internautes de filtrer des résultats lorsqu’ils sont sur une gamme de produits.
Pour le SEO, le moteur de recherche interne est à double tranchant. Nous ferons donc attention à ce qu’il soit bénéfique ou neutre pour le SEO du site.
Bien optimisé, le moteur de recherche interne permettra :
- Une meilleure gestion des recherches et donc un meilleur usage pour les internautes.
- D’être un outil extrêmement performant pour créer de nouvelles pages ‘statiques’ utiles pour le SEO.
- De gérer directement la navigation à facettes.
Si vous souhaitez en savoir plus sur le référencement des sites E-commerce, n’hésitez pas à vous rendre sur notre formation SEO sur le E-commerce.
Les effets pour le SEO
Effets indésirables
Effet négatif potentiel 1 : le moteur de recherche interne va créer de nouvelles urls à chaque fois qu’un internaute fera une recherche : https://www.monsite.fr/page/search_creation/search_creation.php?search_name=test. Le danger de ces urls est lié à leur crawlabilité et leur indexabilité. Si par un moyen quelconque, elles se trouvent être crawlables et indexables par les robots des moteurs de recherche, alors nous aurons des milliers, voire des millions d’urls inutiles crawlées et indexées.
Effet négatif potentiel 2 : l’utilisation du moteur de recherche pour la génération de facettes peut s’avérer dangereuse. Le terme « facette » est apparu dans le jargon des moteurs de recherche pour désigner des requêtes filtrées sur des attributs de la classe d’items stockée dans l’index d’un moteur de recherche.
Dans le contexte d’un site marchand, la classe d’items évoquée plus haut est constituée par le catalogue des produits, et les attributs sont ses caractéristiques (couleur, matière, taille, poids, prix, puissance, etc.)
Une facette est donc un filtre, associé soit à un couple {attribut,valeur} (ex couleur=’rouge’), soit à plusieurs valeurs d’un même attribut (couleur= ‘rouge’ OU couleur=’rose’). Mais on peut définir aussi les valeurs comme des bornes MIN, MAX, ou combinées (prix < 500 euros, ou prix compris entre 100 et 500 euros).
Les filtres attribut x valeur(s) ou attribut x borne(s) de valeur peuvent être combinées pour créer des filtres composites ( [couleur=’rouge’ OU couleur=’beige]’ ET taille=’40’ ET matière=’coton’)
Si l’on vend des vêtements sur un site marchand, on s’aperçoit assez vite que pour des requêtes de type « pull rouge », la meilleure page d’atterrissage est une page de catégorie filtrée par valeur d’attribut : à savoir la catégorie « pulls » filtrée par « couleur=’rouge’ ».
On peut donc être tenté d’associer chaque page de catégorie filtrée par attributs avec une url.
Cette association : page facettée <-> url peut aussi se produire involontairement pour des raisons techniques, notamment si sur le site, les filtres sont appelés sous forme de paramètres passés en mode GET (c’est-à-dire : dans la chaine de paramètres ou query string)
Pour Googlebot, le robot d’exploration de Google, cela signifie qu’il va trouver sur le site un nombre très grand d’urls avec des syntaxes de type :
www.lesitemarchand.com/univers/categ/sous-categ/?couleur=’rouge’&filtreprix=’<500’
ou
www.lesitemarchand.com/univers/?categ=1&couleur=’rouge’&filtreprix=’<500’
ou (syntaxe qu’on préfèrera)
www.lesitemarchand.com/univers/categ/sous-categ/couleur/rouge/filtreprix/moins500 ou …
Selon la syntaxe utilisée sur le site…
Le problème ici, c’est que le nombre de combinaison entre facettes peut très vite faire exploser le nombre de pages…
Prenons un site comportant 2000 produits répartis dans 100 catégories… Classiquement, ce site comportera au départ au maximum 2500 pages, dont 2000 pages produits.
Maintenant, imaginons que ces produits soient des vêtements, disponibles dans 10 tailles, 5 couleurs, 5 matières, et dans 5 segments de prix, et provenant d’une trentaine de marques…
Chaque page de catégorie génère à présent potentiellement :
- 1 x 10 x 5 x 5 x 5 x 30 = 37500 pages filtrées différentes ! Soit 3 750 000 pages de listings pour tout le site !
Et encore, le nombre d’urls peut être encore plus grand si on « permute » l’ordre des paramètres dans les urls, ce qui arrive souvent lorsque les facettes sont ouvertes par accident en passant les paramètres en mode GET…
Effets positifs : Searchdexing, facettes et usage
À l’instar de tous les points négatifs que nous venons d’évoquer, le moteur de recherche interne peut également avoir des impacts positifs sur le SEO.
- Facettes : nous avons vu le cas où les facettes pouvaient générer des milliers d’urls inutiles et indésirables, mais si elles sont correctement gérées, elles peuvent aussi être très utiles pour le SEO. En effet avec des règles d’ouverture et de fermeture strictes permettent de générer des pages qui regroupent plusieurs filtres. Eg : Longue robe rouge taille fine.
Ainsi nous augmentons le nombre de pages de manière naturelle et positive pour le positionnement longue traine notamment.
- Searchdexing : le searchdexing permet, de manière automatique, de créer des pages utiles à l’internaute et au SEO. Le principe est le suivant : les internautes font 100 fois la même requête sur le moteur de recherche en un mois. Or, pour cette requête aucune page statique et référençable n’existe. Le searchdexing va permettre de créer automatiquement cette page et la lier en interne. Il s’agit donc d’établir des règles arbitraires « si la requête XXXX est tapée XXX fois dans le moteur de recherche sur une période maximum de XXXX jours alors je construis la page et la lie en interne ».
- Usage : le moteur de recherche interne peut également permettre d’améliorer l’usage sur vos pages. Il y a deux conditions à cela : le moteur doit proposer des suggestions ; autant que possible, le moteur de recherche doit proposer des pages qui existent déjà dans la structure du site.
- Suggestions : le moteur de recherche interne doit proposer des produits, des catégories, des pages lorsque l’internaute commence à taper sa requête. Les pages suggérées doivent, autant que possible, être des pages présentes dans la structure du site. Ainsi, un internaute qui recherche « Haricots bonduelle » aura une suggestion adaptée qui le mènera non pas vers une page recherche, mais directement vers la page : https://monsite.fr/haricot-bonduelle ainsi nous créons de l’usage sur nos pages plutôt que sur des pages de recherche, inutiles pour le SEO.
En bref, le moteur de recherche idéal :
- Permets une gestion fine des facettes.
- À une tolérance orthographique adaptable.
- Gère la synonymie.
- Fait des suggestions basées sur de la data.
- Permet de récupérer de la data pour faire du searchdexing.
- Génère des urls distinctes pour les bloquer aux robots d’exploration.
- Propose du Searchandising (voir plus loin).
- Est rapide.
- Peut pointer vers du contenu existant.
- S’adaptera en fonction des besoins métiers particuliers.
Les différents types de moteurs de recherche interne
Classiquement, les systèmes de navigation à facettes sont gérés par 4 types de technologie de moteur de recherche interne :
– Des SGBDR (Mysql, Sql Server)
– Des outils de Searchandising (Sparkow, Endeca…)
– Des outils de recherche interne avancés (Exalead, Antidot, Autonomy, SolR, Elastic Search)
– Des outils sémantiques (Sinequa, Synomia, Inbenta….)
SGBDR
Ces outils s’avèrent souvent limités dès lors qu’il s’agit d’exploiter des systèmes de filtres. On peut « reproduire » des fonctionnements avancés, mais cela demande beaucoup de développements supplémentaires. Et il faut aussi réinventer la roue pour optimiser le requêteur d’un point de vue performances.
C’est donc un choix possible (Mysql ici donc), mais qui limitera les possibilités.
Searchandising
Ce sont des outils de recherche interne conçus pour faciliter la vie de gros ecommerçants gérant des catalogues de produits physiques important.
Ils gèrent nativement les filtres et les facettes. On entend également par Searchandising la possibilité de proposer des produits ou catégories en suggestion sans avoir à recharger la page.
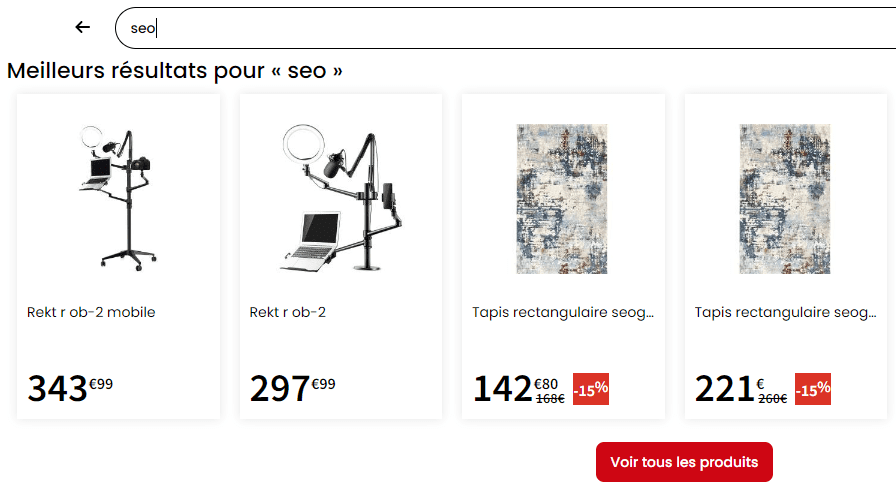
Exemple de Searchandising sur Conforama :
Les moteurs de recherche avancés
Tous ces outils peuvent indexer des données structurées, et restituer des résultats filtrés par facettes efficacement.
Les moteurs de recherche « sémantiques »
Ces moteurs peuvent apporter des fonctionnalités intéressantes, mais encore faut-il qu’ils répondent aux besoins du client .
Les MRI adaptés à nos besoins
ElasticSearch
ElasticSearch est un moteur de recherche interne qui a plus de 10 ans maintenant, il a donc subi de nombreuses évolutions, mais son cœur reste basé sur Lucene, librairie JAVA open source qui permet d’indexer et de recherche du texte (le fonctionne d’un MRI classique donc). Il est open source et donc très fortement personnalisable. Attention, malgré le fait qu’il soit open source, la communauté n’a pas 100% accès à son code. Il est possible de proposer des changements, mais ils sont finalement validés ou non par des employés d’Elastic.
Il est scalable, c’est-à-dire qu’il s’adapte en fonction des besoins. S’il s’agit d’indexer et de recherche parmi des centaines de milliers (voire plus) de documents, alors il faut ajouter des machines à Elastic Search et il pourra ensuite répartir la charge convenablement.
Une possibilité intéressante d’ElasticSearch c’est de le coupler avec Kibana et Logstash (le stack ELK) afin de visualiser en temps réel les hits se trouvant dans les logs du site. La couche Logstash (utilisée pour les access logs) n’est pas obligatoire et dans ce cas nous avons un couple Elastic + Kibana qui permet de faire de la visualisation des données présentes dans ElasticSearch.
ElasticSearch efficace lorsqu’il s’agit de faire des « Analytical queries » c’est-à-dire, combiner différentes requêtes de différentes sources dans un seul « set » de résultats.
Apache SolR
SolR est aussi un moteur de recherche assez ancien, qui a un peu plus de 10 ans maintenant. Il a également subi de nombreuses évolutions. Il est aussi basé sur la bibliothèque Lucene et est donc open source. Contrairement à ElasticSearch, il est open source à 100%. Autrement dit, il est possible pour la communauté de changer le code de SolR pour proposer des nouvelles fonctionnalités et diverses améliorations.
SolR est scalable tout comme ElasticSearch. Lorsqu’une grande quantité de donnée doit être traitée, il suffit alors d’ajouter de la puissance de calcul à SolR pour qu’il puisse répartir la charge convenablement.
SolR est nativement efficace sur la gestion des fautes d’orthographe, l’auto complétion et le searchandising.
SolR a globalement une communauté très large et une documentation très fournie et détaillée qui permet une prise en main complète sans trop de difficultés.
De manière générale, SolR et ElasticSearch sont très similaires, ElasticSearch étant un peu plus lourd et difficile à prendre parfaitement en main. La véritable différence entre les deux se fera surtout par la capacité des équipes à prendre en main l’un ou l’autre.
Algolia
Algolia c’est le petit nouveau dans les moteurs de recherche interne. La solution créée en 2012 est aujourd’hui déjà très répandue sur le web, même si elle n’est pas encore au niveau de ses 2 concurrents évoqués plus haut.
Algolia est une solution cloud payante. Impossible donc de faire ses propres développements, il faudra donc compter uniquement sur ce qui est déjà développé. La solution étant payante et cloud, les équipes sont relativement réactives lorsqu’il s’agit d’aider à la compréhension d’une fonctionnalité ou autre.
La principale force d’Algolia c’est d’être basé sur une technologie JS. Ce qui lui permet, avec InstantSearch par exemple, d’être plus rapide dans l’affichage des résultats que tous ses concurrents.
Algolia est également conscient des enjeux SEO autour des moteurs de recherche interne. Par exemple, ils intègrent nativement des balises canonical sur les pages de résultats de recherche vers la page de Search originale.
Algolia est donc un très bon moteur de recherche interne pour l’expérience utilisateur. Son gros point faible réside dans la gestion des facettes. Il est tout à fait possible d’utiliser Algolia pour la gestion des facettes, mais puisqu’il s’agit d’une technologie JS, cela complique tout et rend les facettes quasiment invisibles pour les moteurs de recherche.
Des solutions de contournement sont possibles, mais très imparfaites pour le moment et nécessitent donc un travail supplémentaire.
Notre recommandation :
Notre recommandation serait d’utiliser SolR :
- Il est suffisamment avancé pour produire des résultats plus pertinents qu’un SGBDR
- Il est hautement flexible et peut répondre à des besoins encore plus avancés dans le futur
- Son coût de possession est faible (pas de licence) et on trouve de plus en plus facilement des ressources maitrisant SolR
- Sa gestion des facettes et de l’indexation des données structurées est bonne.
- La volumétrie à gérer est compatible avec un SolR non optimisé.
Attention cependant, comme indiqué précédemment, si les équipes sont plus à l’aise avec l’utilisation d’ElasticSearch et sont donc plus à même de le customiser selon les besoins, il est parfaitement envisageable d’utiliser cette technologie plutôt que SolR. Les deux étant très proches, une appétence particulière pour l’un d’eux suffirait à justifier le choix de son utilisation.