RANKBRAIN fonctionne depuis 2 ans, et les SEO le comprennent toujours aussi mal
Ecrit par Marc Grosvalet
le
Google, selon les informations publiées dans un article de Bloomberg en octobre 2015, a commencé à déployer Rankbrain au début de l’année 2015. Cela fait donc deux ans que Google fonctionne en embarquant un outil qui tire parti des dernières avancées en matière d’Intelligence Artificielle. Mais l’IA est un vaste de champ de recherche, pas très bien connu de la plupart des experts SEO, et qui les fait beaucoup fantasmer. Le résultat, c’est que depuis l’annonce de l’existence de Rankbrain par Greg Cerrado, il s’est écrit beaucoup de choses inexactes sur cet outil, son rôle dans l’algorithme et sur son importance.
Il faudrait un très long article pour expliquer complètement tout ce que l’on sait et l’on ne sait pas sur Rankbrain. Mais la plupart des idées fausses des experts SEO proviennent du fait qu’ils ne connaissent pas la méthode au coeur de cet élément de l’algorithme : les « word embeddings »…
De la mesure de similarité textuelle a la similarité « sémantique »
Dans un algorithme de moteur de recherche, on a besoin d’un outil permettant de calculer une note de « similarité » entre deux documents (en pratique : entre un court document constitué par la requête et un document plus long : la page web à classer). Cette note est stratégique pour créer un classement pertinent, mais elle est utilisée en combinaison avec un très grand nombre d’autres signaux, plutôt majeurs (comme la popularité de la page), ou mineurs (comme la présence d’un mot clé dans l’url de la page).
Dans les années 90, l’outil le plus utilisé pour calculer cette similarité textuelle était le « Cosinus de Salton ». Dans cette approche, des vecteurs de coordonnées étaient attribués aux documents, en fonction d’un poids attribué à chaque terme d’un document. Les coordonnées fixaient une position dans un espace dotés d’autant de dimensions que de termes dans le document. Et pour voir si deux documents étaient proches ou non, il suffisait de calculer la distance angulaire entre les deux vecteurs grâce au fameux « Cosinus de Salton ».
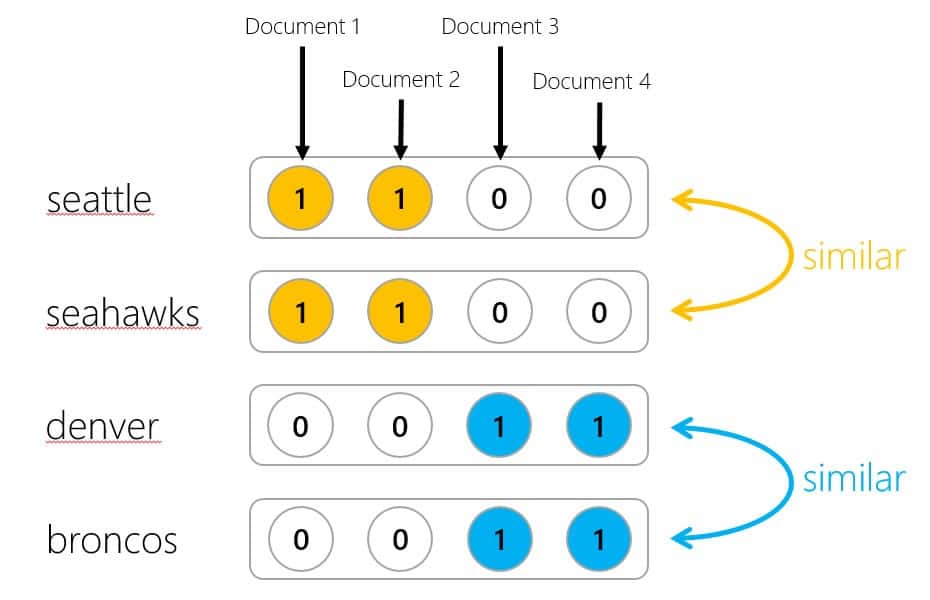
Malgré la lourdeur de la méthode, due à la taille des matrices à manipuler, elle a été massivement employée parce que les ordinateurs savent très bien faire des opérations sur des matrices ou des vecteurs, même de dimension respectable. On l’a donc retrouvée dans différents moteurs comme Altavista ou plus récemment dans Lucène SolR, et une méthode similaire a été employée dans le Google des débuts.
Par contre, cette approche avait un défaut majeur : elle mesure une similarité textuelle, mais ne tient pas compte du sens des termes. Or, avec la multiplication des requêtes en langage naturel, il devient crucial pour continuer d’obtenir des réponses pertinentes de bien comprendre le sens des requêtes, mais aussi, de bien comprendre ce que traite le contenu d’une page web pour renvoyer les plus pertinentes.
Bref, on a besoin d’un outil de calcul de similarité entre documents qui tienne plus compte du sens des termes.
Le concept de « word embeddings »
Les premières descriptions théoriques d’outils permettant d’extraire par le calcul des relations sémantiques entre les termes datent des années 60. L’idée consistait à analyser de manière statistique les contextes dans lesquels les termes apparaissaient.
Les premières approches ont consisté à utiliser des outils de calcul de type Analyse en Composantes Principales. Cela a donné en 1988 la méthode « LSA/LSI » redécouverte dans les annéees 2005/2006 par les référenceurs (mais mal comprise à l’époque, sauf exception) et plus tard la méthode LDA.
Le problème de ces méthodes, c’était leur manque de scalabilité (impossible de les appliquer à très grande échelle), et le fait que la nature des relations sémantiques découvertes étaient difficiles à identifier et donc à utiliser en pratique. Pendant des dizaines d’années, calculer une similarité « sémantique » a donc buté sur des problèmes de méthode de calcul.
L’apport de l’intelligence artificielle
Dans les années 2005/2006, des chercheurs (notamment chez Google) ont eu l’intuition que les avancées en matière d’intelligence artificielle leurs donnaient des outils nouveaux leur permettant de résoudre le problème de l’analyse des contextes. L’idée était d’appliquer des méthodes de calcul à base de réseaux de neurones et d’exploiter l’approche dite des « word embeddings » à ce problème. Ces recherches ont donné Word2vec, une méthode de calcul des coordonnées d’un terme dans un espace vectoriel sémantique, inventée par Tomas Mikolov de Google.
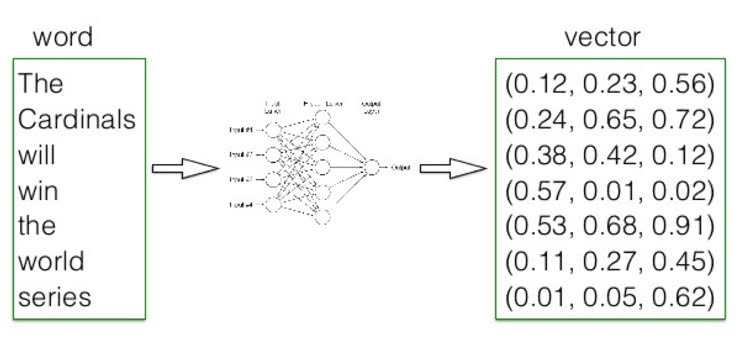
Les résultats se sont révélés bluffants. Et les applications se multiplient dans de nombreux domaines :
- la traduction automatique
- l’analyse du sentiment
- la reconnaissance vocale et le traitement automatique des langues
- et bien sur, les outils de recherche (=> Rankbrain)
Rankbrain : l’IA est dans le calcul, le reste est classique
Avec une méthode comme les word embeddings, les termes et les documents sont associés à des vecteurs. Et la similarité sémantique est aussi calculée à l’aide d’une méthode de type Cosinus. Bref, les résultats de cette approche nouvelle et sophistiquée peuvent être exploitée avec des méthodes familières pour les gens qui construisent des algorithmes de moteur de recherche.
Est-ce que Rankbrain remplace l’algorithme traditionnel : pas du tout. Il le complète. Il est utilisé pour améliorer la compréhension de la requête et des termes utilisés dans la requête. Et pour améliorer la pertinence des résultats remontés.
Sur la plupart des requêtes les calculs de similarité textuelle et les signaux traditionnels (dont le fameux « Pagerank ») sont suffisants pour obtenir des résultats pertinents. Mais sur certaines requêtes ambigües, et/ou formulées en langage naturel, les infos tirées des « word embeddings » sont indispensables pour faire remonter les pages les plus pertinentes.
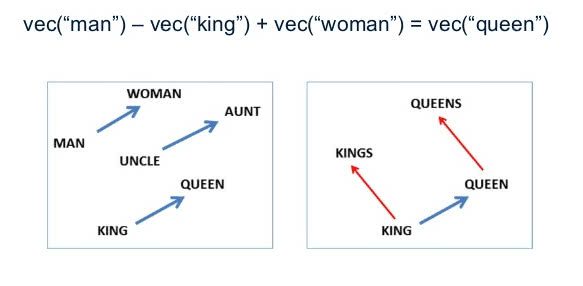
Une application des word emebddings : deviner un mot proche sémantiquement. Si je soustrais du vecteur pour « man » le vecteur pour « king » et que j’ajoute le vecteur pour « woman », je trouve les coordonnées du mot associé à woman pour king : queen
Les « word embeddings » : un domaine de recherche des SF Labs
Chez Search Foresight, nous considérons les « word embeddings » comme les prémices d’une révolution qui va considérablement changer le fonctionnement des outils de recherche dans les années à venir, et donc aussi, les méthodes d’optimisation pour les moteurs de recherche. Notre équipe des SF Labs a donc étudié ces outils et les concepts sous jacents pendant toute l’année 2016. Et nous envisageons de sortir les premières applications concrètes pour vos sites web en 2017. Alors restez à l’écoute, nous en reparlerons bientôt sur ce blog.
Pour en savoir plus :
- https://fr.wikipedia.org/wiki/Word_embedding
- http://s.billard.free.fr/referencement/?2006/10/09/296-ne-prenez-pas-lsi-pour-des-lanternes-par-philippe-yonnet
- https://fr.wikipedia.org/wiki/Analyse_s%C3%A9mantique_latente
- https://fr.wikipedia.org/wiki/Allocation_de_Dirichlet_latente