Google utilise le neural matching dans son algorithme. Mais c'est quoi, le neural matching ?
Ecrit par Mathieu CHAPON
le
Parmi les annonces effectuées à l’occasion du 20e anniversaire de Google en septembre dernier, Danny Sullivan a révélé que Google utilisait depuis plusieurs mois le « neural matching » dans son algo. A l’occasion de la mise à jour récente du 12 mars, certains ont évoqué la possibilité que cette technologie ait joué un rôle dans les bouleversements de classement observé (ce que Google a démenti d’ailleurs).
Mais c’est quoi le « neural matching » ? Nous allons voir que c’est à la fois tout sauf une révolution (c’est plus une évolution) des techniques utilisées par les moteurs de recherche, et nous allons pointer du doigt les erreurs d’interprétation que j’ai pu relever ici et là chez les SEOs.
Le « neural matching » : un avatar de techniques parfaitement connues
La « correspondance neuronale » est un terme vague que Google emploie probablement pour brouiller les pistes. Mais il est clair que cela fait allusion à l’emploi de réseaux de neurones pour une tâche que Danny Sullivan a désigné sous le nom de « ad hoc retrieval ».
L' »extraction ad hoc », c’est le nom scientifique donné à une tâche particulière que les moteurs de recherche comme Google doivent effectuer pour fabriquer une page de résultats : extraire de son index une liste de pages webs ordonnée en fonction de sa pertinence en réponse à une requête.
La solution classique est d’utiliser des méthodes de calcul de similarité entre la requête et les documents, en se basant sur les termes contenus dans l’expression tapée et dans les pages webs. Mais cette méthode, qui fonctionne suffisamment bien pour avoir été utilisée depuis les années 60 et jusqu’à aujourd’hui dans les moteurs, a deux inconvénients :
- comme les requêtes contiennent peu de termes, les résultats jugés « similaires » ne sont pas tous d’une grande pertinence
- la méthode ne permet pas à des pages web qui sont de bonnes réponses de remonter en tête des classements si elles ne contiennent pas vraiment les termes de la requête

Un exemple classique : les deux textes ci dessus ont les mêmes scores de similarité (Cosinus de Salton) sur la requête « Albuquerque », sauf que le premier est pertinent mais pas le second. Les méthodes de neural information retrieval permettent de dégager le sens latent (sous jacent, caché), et d’identifier le texte a comme le seul texte pertinent
Cela fait donc de nombreuses années que les chercheurs en « information retrieval » cherchent des solutions alternatives plus efficaces. Ils ont pensé tenir une piste au début des années 2000 avec les approches LDA (Latent Dirichlet Allocation) et LSI (Latent Semantic Indexing), mais cela n’a pas donné d’applications solides pour l' »ad hoc retrieval ». Il a fallu attendre la révolution apportée par l’utilisation des réseaux neuronaux aux problèmes de linguistique pour voir de premières intégrations se dessiner. Notamment avec la méthode des « word embeddings » que l’on retrouve dans Rankbrain, un composant de l’algo de Google depuis 2016.
Ce que décrit Google avec le neural matching n’est que le résultat de l’évolution de l’état de l’art : aujourd’hui, on sait mieux analyser le « sens » des termes inclus dans les requêtes, ainsi que dans les pages webs. Dans la pratique, les méthodes utilisent à présent des analyses séparées puis combinées. On sait mieux également associer les informations fournies par les méthodes à base de réseaux neuronaux à celles fournies par les méthodes classiques, pour obtenir des pages de résultats plus pertinentes qu’avant.
Danny Sullivan a récemment précisé la différence entre Rankbrain et le Neural Matching : RankBrain aide Google à mieux relier les pages aux concepts ; Neural matching aide Google à mieux relier les mots aux recherches….
We’ve had some questions about how neural matching differs from RankBrain. In short: RankBrain helps us better relate pages to concepts; Neural matching helps us better relate words to searches…
— Google SearchLiaison (@searchliaison) March 21, 2019
Les deux approches font partie d’une nouvelle discipline dans la science cachée derrière les algos de classement des moteurs de recherche que les chercheurs appellent « Neural Information Retrieval » (l’extraction d’informations à base de réseaux de neurones).
Qu’est-ce que cela change concrètement ?
L’intégration dans l’algorithme du Neural IR en général et du Neural Matching a deux conséquences importantes pour le référencement.
- il n’est plus obligatoire d’avoir les mots clés de la requête dans le contenu de la page pour sortir en tête des résultats. Danny Sullivan a cité un exemple frappant, où sur la requête « why does my tv look strange » ressortent des pages parlant de l’effet « soap opera » (un effet produit par les télés en Ultra Haute Definition qui donnent l’impressionqu’un film des années 70 a été tourné en video !)
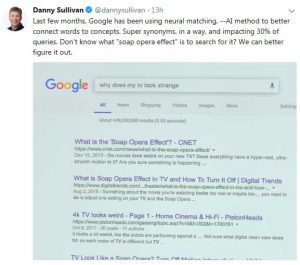
- D’une manière générale, les méthodes à base de réseaux de neurones s’appuyant beaucoup sur le contexte, en en tirant des informations sur le sens précis des mots dans ce contexte, truffer une page de synonymes mal choisis fonctionne beaucoup moins bien qu’avec les méthodes classiques

Un exemple donné par Danny Sullivan : dans toutes ces questions, le sens du terme « change » est différent. Le sens est donné par le contexte. Les méthodes d’analyse sémantique à base de réseaux de neurones permettent d’identifier l’acception correcte pour le terme
Pourquoi Search Foresight connait bien ces méthodes ?
Le labo de recherche SF Labs de Search Foresight travaille depuis 2016 sur ces sujets, dans le cadre de projets financés par le CIR (Crédit Impôt Recherche). Dans un premier temps, nous avons étudié les applications possibles des word embeddings (voir à ce sujet la présentation de ma conférence de vulgarisation au SEO Camp’us de Lyon en 2017)
Puis plus récemment, nous avons entrepris de faire quelques POCS réutilisant nos travaux chez certains de nos clients. Mais l’état de l’art évoluant, depuis l’année dernière nous travaillons sur de nouvelles approches plus efficaces pour résoudre certains problèmes, dont certaines sont probablement très proches de ce que Google nomme « le neural matching ».
Promis, nous programmons un webinar en juin sur le sujet, dont l’objectif sera de vous expliquer comment ces technologies peuvent aussi servir pour le SEO, le PPC. et pour améliorer l’expérience de vos utilisateurs sur vos sites webs.