Google BERT vue par les Data Scientists de Search Foresight
Ecrit par Mathieu CHAPON
le
Cet article a été rédigé en collaboration avec nos équipes data qui utilisent depuis 2019, l’algorithme de BERT pour l’analyse des intentions de recherche pour les outils de l’agence.
Depuis l’avènement du mobile, les requêtes ont beaucoup évolué et une proportion importante de nouvelles recherches apparait chaque jour. Google estime que chaque jour, 15% des requêtes sont en fait de nouvelles requêtes.
Or, si Google découvre autant de nouvelles données chaque jour, on peut aisément imaginer que cela devient de plus en plus complexe de définir quel(s) critère(s) sélectionner pour proposer un résultat pertinent pour l’internaute.
C’est là que le machine learning prend tout son sens
Lorsqu’on a des milliards de données à analyser en temps réel : les requêtes connues, les classements de sites sur ces recherches, l’indexation de milliards de pages avec des données sur l’usage de vos utilisateurs à analyser doit nécessairement s’anticiper. L’une des solutions est d’entraîner un modèle de machine learning pour être capable de répondre, en un temps record, à des nouvelles situations comme les 15% de nouvelles requêtes quotidiennes.
Google a lancé en 2015, son I.A. appelée Rankbrain. Cette intelligence artificielle est capable de répondre instantanément et de manière autonome à ces nouvelles recherches. D’ailleurs, les ingénieurs de Google nous expliquent que :
« … RankBrain est devenu le troisième signal le plus important contribuant au résultat d’une requête de recherche. »
Mais étonnement
« Même nous (les ingénieurs de Google) ne comprenons plus en détail, le fonctionnement du moteur »
Il faut bien comprendre que si des requêtes n’ont jamais été vues auparavant, les résultats de ces recherches ne peuvent pas être préparés. Google doit d’abord les comprendre et trouver les meilleurs résultats satisfaisants à montrer aux utilisateurs. D’où une IA pour s’appuyer sur l’expérience passée et fournir un résultat qui se rapproche des expériences déjà vécues sur les résultats de recherche.
Des requêtes de plus en plus complexes
Récemment, l’équipe de recherche de Google qui travaille sur le traitement du langage naturel (NLP) a créé un algorithme utilisant des techniques issues du « Deep Learning » appelées BERT (« Bidirectional Encoder Representations from Transformers »). BERT est un modèle pré-entraîné qui permet de répondre de manière plus aboutie à un large éventail de tâches de NLP tel que les réponses aux questions, la similarité sémantique, la classification, etc
Qu’est-ce que BERT techniquement ?
Il s’agit d’un modèle bidirectionnel, car, contrairement aux modèles directionnels de NLP qui lisent le texte dans un sens particulier (par exemple de gauche à droite), ce nouveau modèle parcourt le texte dans sa totalité et dans les deux directions en une seule fois, d’où la caractérisation de « bidirectionnel ». Techniquement, BERT est constitué de multiples couches formant un « Transformer » qui apprend des relations contextuelles entre les différents mots composant le texte. Il utilise un encodeur pour lire le texte d’entrée et ainsi générer une représentation vectorielle des mots et un décodeur spécifique pour effectuer la tâche de prédiction escomptée.
Dans quelle mesure Google comprend-il mieux une requête en utilisant BERT ?
BERT utilise les techniques mentionnées pour mieux comprendre l’intention des requêtes des utilisateurs. Les requêtes peuvent être écrites ou orales.
Pour BERT, chaque mot est important et sa signification est interprétée en tenant compte des mots voisins dans la requête. Par exemple, contrairement à l’ancienne méthode, l’utilisation de prépositions comme « de » ou « pour » dans la requête a désormais beaucoup d’importance aux yeux de BERT. Au lieu de les éliminer, BERT utilise la relation entre ces prépositions et les autres mots de la requête pour mieux comprendre la requête de l’internaute.
Voici un exemple fourni par Google pour illustrer le fonctionnement de BERT. Dans la requête « 2019 Brazil traveler to usa need a visa », le mot « a » joue un rôle important. Grâce à BERT, Google est capable de considérer l’importance de la préposition « to » ce qui lui permet d’afficher les résultats sur les voyageurs brésiliens aux États-Unis. À titre de comparaison, lorsque la préposition « to » est ignorée cette même requête affiche l’inverse : les résultats sur les voyageurs américains au Brésil.
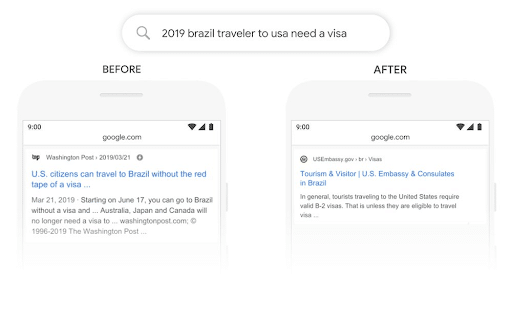
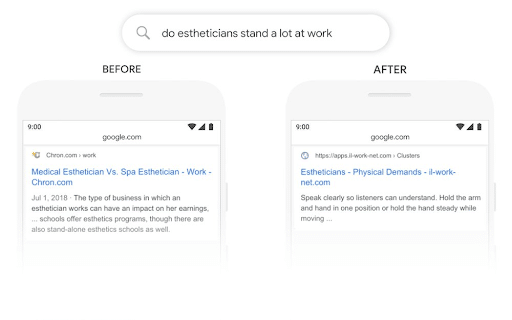
Évidemment, BERT est bien plus qu’un simple traitement des prépositions. Il comprend la signification de chaque mot dans le contexte d’une requête donnée. Pour plus de clarté, référons-nous à un autre exemple de Google. Dans l’image ci-dessous, BERT comprend que le sens de « stand » est lié à un travail, alors qu’auparavant, Google extrayait les mots-clés de la requête et remplaçait « stand » par des mots-clés correspondants comme « stand-alone » (cela peut être dû au fait que « stand a lot » est considéré comme une coquille utilisateur pour « stand-alone »).
En résumé, le modèle BERT vise à mieux comprendre l’intention de l’utilisateur à travers sa requête.
BERT du point de vue du référencement
Comme BERT comprend mieux l’intention de l’utilisateur, il est important que le contenu des pages soit en corrélation avec les attentes de l’internaute. La stratégie éditoriale doit donc prendre en compte ce nouveau paradigme et se recentrer davantage sur l’intention des internautes, ce qui favorisera un trafic plus pertinent et une meilleure visibilité de vos contenus.