Générer du contenu en JS côté client n'est vraiment pas une bonne idée
Ecrit par Mathieu CHAPON
le
Cela fait déjà un moment que Google prétend savoir crawler et indexer des contenus générés en Javascript. Cela pourrait être vu comme une bénédiction, tant la mode des frameworks Javascript (AngularJS, ReactJS, EmberJS) semble se répandre chez les développeurs comme une traînée de poudre.
Sauf que l’exercice a ses limites, et qu’on commence à mieux connaître et comprendre ces limites.
A tel point que l’on peut aujourd’hui affirmer que générer du contenu JS client, ce n’est définitivement pas une bonne idée.
Pourquoi ? Et bien faisons le point sur les problèmes que créés cette pratique calamiteuse pour le SEO.

Seul Googlebot est capable de crawler ou d’indexer le contenu généré en javascript côté client
Rappelons tout d’abord que Googlebot est l’un des rares bots à être capable de crawler et d’indexer du contenu généré en JS. Bingbot a un support tellement anecdotique du JS qu’il vaut mieux considérer qu’il ne sait pas faire, et quant aux autres robots d’exploration, les choses sont claires : ils ignorent superbement ce type de contenu !
Bref, si vous avez besoin de référencer un site aux USA ou en Russie, et bien, oubliez cette jolie technologie pratique et élégante qu’essaient de vous vendre vos développeurs, à savoir un site fait 100% à base de frameworks JS tournant côté client !
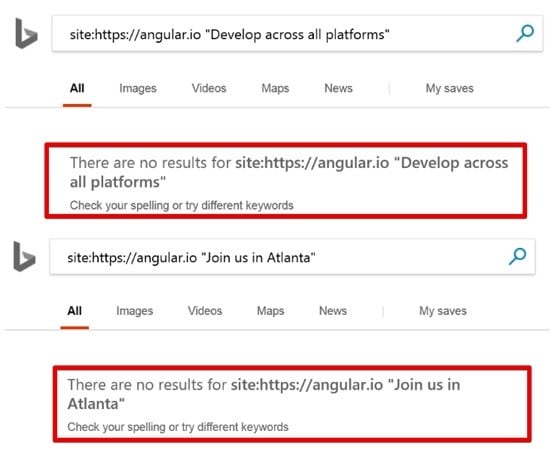
Googlebot a de sérieuses limites lorsqu’il crawle et indexe du javascript
Il est possible que vous vous fichiez des USA ou de la Chine et que votre site ne cible que la France ou l’un de ces nombreux pays d’Europe où Google représente plus de 90% de parts de voix. Et peut-être vous dîtes vous : puisque Google me dit qu’ils savent crawler et indexer le Javascript, tout va bien se passer pour mon site en Full Angular 1 !
Dans la pratique, ce n’est pas vrai du tout !
Déjà, crawler et rendre du Javascript demande des ressources beaucoup, beaucoup plus importantes qu’un crawl traditionnel. Un site fait avec un framework JS verra son contenu indexé plus lentement, mis à jour plus lentement… Et là on parle de jours, et pour l’avoir vu sur des exemples, d’une dizaine de jours potentiellement avant que les modifications de votre contenu générés en JS soient prises en compte !
Ce point a été confirmé récemment lors d’un hangout sur le sujet présenté à l’occasion du dernier Google I/O
En fait, le contenu généré en JS n’est pas indexé tout de suite, mais seulement dans un deuxième temps, une fois que les ressources nécessaires deviennent disponibles.
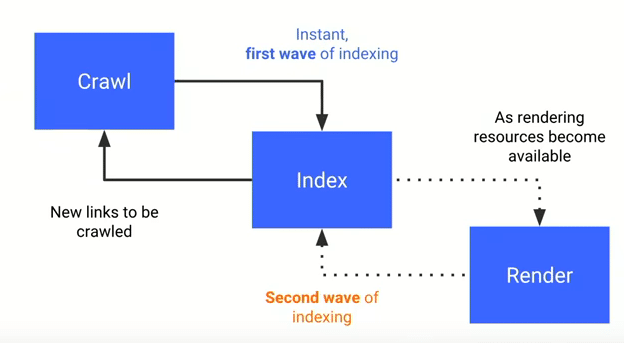
Bref, si vous voulez que vos actualités soient indexées rapidement, débrouillez-vous autrement et oubliez les frameworks JS côté client.
L’indexation est … aléatoire
Pour couronner le tout, il n’est pas sûr que le contenu généré en JS soit réellement correctement indexé ! Dans la pratique, on voit que ce n’est souvent pas le cas.
Bon évidemment, s’il y’a la moindre erreur dans le code JS, cela empêchera la rendition du contenu, et donc son indexation.
Mais même si votre code est parfait, il n’est pas sûr que ça fonctionne : en effet, Google n’indexera vos contenus qu’à deux conditions :1. Votre contenu doit être généré dans un délai raisonnable : moins de cinq secondes à l’expérience, sinon le bot abandonne la partie et tant pis pour les textes optimisés que vous avez amoureusement concoctés, Google les ignorera superbement
2. Et votre contenu doit être généré dans le premier état de la page : s’il faut une action complémentaire pour le charger, comme un clic de l’utilisateur, c’est mort
Et il y’a des balises que Google ne lit que si elles figurent dans le HTML statique
Qui plus est, John Mueller a récemment confirmé que la balise canonical notamment n’était prise en compte que si elle figurait dans le code HTML statique disponible pour le bot classique (le premier code HTML téléchargé par le navigateur). Si elle est générée en Javascript, Google l’ignore.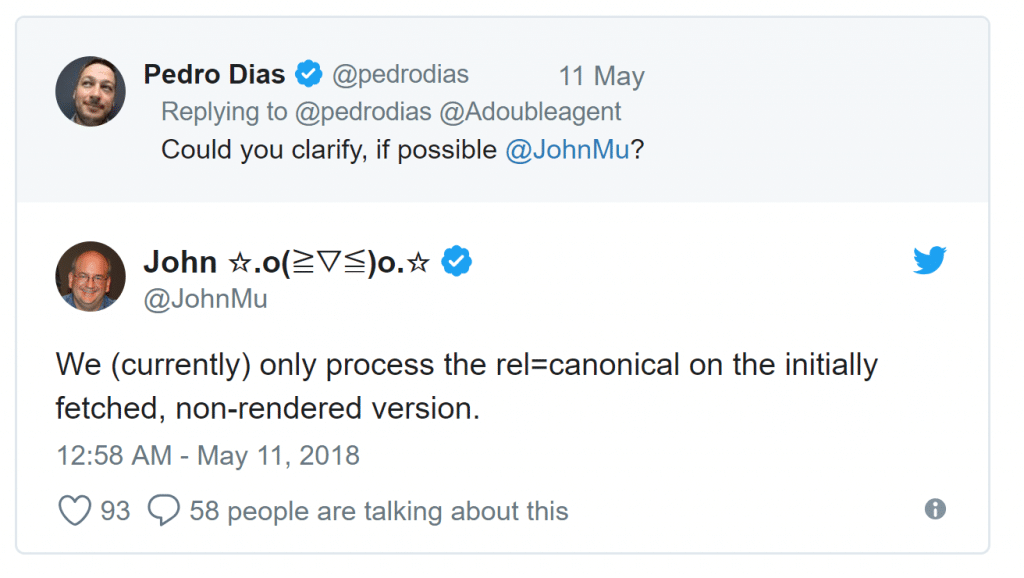
J’en profite pour signaler que toutes les techniques données ici et là pour injecter des balises SEO en utilisant Google Tag Manager ne sont que des béquilles qui ne marchent pas toujours.
En particulier, si vous essayer d’ajouter le balisage schema.org via GTM, il est fréquent que Google l’ignore, alors que si vous les injectez dans le HTML statique, vous êtes sûr que Google les lira correctement.
Même chose pour d’autres balises. Nous sommes en train de faire des tests plus systématiques chez SF pour avoir une idée plus claire de ce qui marche ou non et pourquoi.
Alors, on oublie les frameworks javascript ?
Bon puisque c’est si terrible, faut-il s’interdire les frameworks javascripts pour avoir un bon référencement ?
NON ! Il y’a trois modes d’implémentation possibles, et seulement un est à proscrire :
– le CSR : le Client Side Rendering. Le contenu est généré intégralement dans votre navigateur en JS. C’est cette implémentation qui est à proscrire
– le SSR : le Server Side Rendering. Le contenu est généré intégralement côté serveur. Votre navigateur reçoit un contenu complet en HTML généré comme d’habitude. Cette implémentation ne pose a priori aucun problème de SEO
– l’approche « hybride ». Une partie du contenu est générée côté serveur. Le reste côté client. Si ce qui est généré côté serveur comporte toutes les balises SEO et le contenu que vous voulez voir crawler et indexer, cette approche ne pose la aussi aucun problème pour le SEO
Bon, aujourd’hui, la plupart des sites faits avec un framework JS sont plutôt des CSR ou des méthodes hybrides mal fichues pour le SEO : l’éducation des développeurs va prendre du temps.
C’est d’ailleurs probablement à cause de cela que Google veut introduire le concept de dynamic rendering : une façon de générer du contenu en SSR pour les bots, et du CSR pour les utilisateurs. Le système s’appuie sur Puppeteer et Rendertron, deux outils développés chez Google. Mais c’est une fausse bonne idée selon moi, comme l’était la méthode des hash bangs !
Donc non, par pitié, dites à vos développeurs qu’ils peuvent continuer à se faire plaisir avec les frameworks javascript, mais à la condition expresse de faire du SSR !
Les outils pour faire du dynamic rendering
L’intervention de Tom Greenaway lors du Google I/O
L’outil puppeteer
L’outil rendertron