Non, on ne résout pas tous les problèmes de duplicate avec des canonicals !
Ecrit par Marc Grosvalet
le
Il est de plus en plus fréquent de voir des webmasters essayer de résoudre tous leurs cas de duplication de contenu avec une balise <link rel=’canonical’…>. La raison invoquée c’est que c’est plus facile à mettre en oeuvre q’une redirection 301, ou de traiter la cause de la duplication de contenu,
Mais le problème c’est que cela ne marche pas à tous les coups…
Pourquoi ?
La balise link rel canonical n’est pas une directive, c’est juste une indication
Depuis l’apparition de cette balise, Google le dit et le répète : cette balise donne une indication (« a hint » en anglais) à Google, que le moteur peut ensuite librement décider d’exploiter.
Ce n’est pas une directive que le moteur doit respecter impérativement.

Le résultat, c’est qu’utiliser des link rel canonical ne garantit jamais que les problèmes de duplication de contenus soient résolus. Il faut donc considérer cela comme une solution à employer quand on a pas d’autres choix. Sinon, il vaut mieux véritablement traiter la cause de la duplication, ou mettre en place des redirections 301.
Vous ne me croyez pas ? Voila ce que vous dit un porte parole de Google
John Mueller l’avait rappelé dans un hangout récent : dans le cas où les deux pages ont en fait des contenus différents (les deux pages ne sont pas de vrais doublons, ce sont des quasi doublons ou même des pages en réalité différentes), Google peut décider de ne pas tenir compte de la balise canonical ! Et c’est un comportement normal,
Comment diagnostiquer qu’une balise canonical est ignorée par Google
Il est assez facile de voir si Google respecte vos urls canoniques ou non.
Tout d’abord il faut identifier toutes les pages d’atterrissage de votre site qui reçoivent du trafic issu des moteurs de recherche.
On peut les obtenir via la Google Search Console. Si vous en avez beaucoup, je vous rappelle que vous pouvez contourner la limite des 1000 résultats du rapport en ligne en passant par l’API ou par un outil de type Analytics Edge ou Supermetrics.
Vous pouvez aussi exploiter l’information de vos logs ou de votre solution de web analytics.
Si une url canonicalisée vers une autre url est active (cette page d’atterrissage reçoit du trafic), c’est donc qu’elle figure dans l’index et dans des pages de résultats. Donc que la balise canonical est… ignorée !
On peut identifier facilement ces cas avec un outil comme Botify en créant un rapport sur les pages actives canonicalisées.
Pour des sites comportant moins de 50000 urls, on peut aussi s’aider d’un crawl Screaming Frog connecté au web analytics et à la search console pour identifier ces mêmes pages
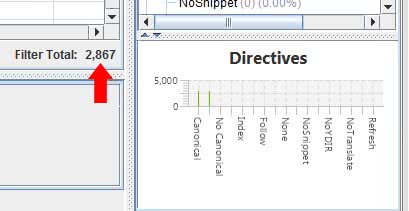
Testez cette méthode sur votre site et vous aurez peut-être une mauvaise surprise : ces cas sont moins rares qu’on ne le pense…
Pour en savoir plus :
Le lien vers le hangout de John Mueller (aller directement à 33’31 »)
La page support de Google sur les urls canoniques